一、读取数据存到 MySQL
1.MySQL 中创建表
[oracle@hadoop102 ~]$ mysql -uroot -p000000
mysql> create database oracle;
mysql> use oracle;
mysql> create table student(id int,name varchar(20));
2.编写 datax 配置文件
[oracle@hadoop102 ~]$ vim /opt/module/datax/job/oracle2mysql.json
{
“job”: {
“content”: [
{
“reader”: {
“name”: “oraclereader”,
“parameter”: {
“column”: [“*”],
“connection”: [
{
“jdbcUrl”:
[“jdbc:oracle:thin:@hadoop102:1521:orcl”],
“table”: [“student”]
}
],
“password”: “000000”,
“username”: “atguigu”
}
},
“writer”: {
“name”: “mysqlwriter”,
“parameter”: {
“column”: [“*”],
“connection”: [
{
“jdbcUrl”: “jdbc:mysql://hadoop102:3306/oracle”,
“table”: [“student”]
}
],
“password”: “000000”,
“username”: “root”,
“writeMode”: “insert”
}
}
}
],
“setting”: {
“speed”: {
“channel”: “1”
}
}
} }
3.执行命令
[oracle@hadoop102 ~]$
/opt/module/datax/bin/datax.py /opt/module/datax/job/oracle2mysql.json
4.查看结果
mysql> select * from student;
+——+———-+
| id | name |
+——+———-+
| 1 | zhangsan |
+——+———-+
二、读取 Oracle 的数据存入 HDFS 中
1.编写配置文件
[oracle@hadoop102 datax]$ vim job/oracle2hdfs.json
{
“job”: {
“content”: [
{
“reader”: {
“name”: “oraclereader”,
“parameter”: {
“column”: [“*”],
“connection”: [
{
“jdbcUrl”:
[“jdbc:oracle:thin:@hadoop102:1521:orcl”],
“table”: [“student”]
}
],
“password”: “000000”,
“username”: “atguigu”
}
},
“writer”: {
“name”: “hdfswriter”,
“parameter”: {
“column”: [
{
“name”: “id”,
“type”: “int”
},
{
“name”: “name”,
“type”: “string”
}
],
“defaultFS”: “hdfs://hadoop102:9000”,
“fieldDelimiter”: “\t”,
“fileName”: “oracle.txt”,
“fileType”: “text”,
“path”: “/”,
“writeMode”: “append”
}
}
}
],
“setting”: {
“speed”: {
“channel”: “1”
}
}
} }
2.执行
[oracle@hadoop102 datax]$ bin/datax.py job/oracle2hdfs.json
3.查看HDFS结果
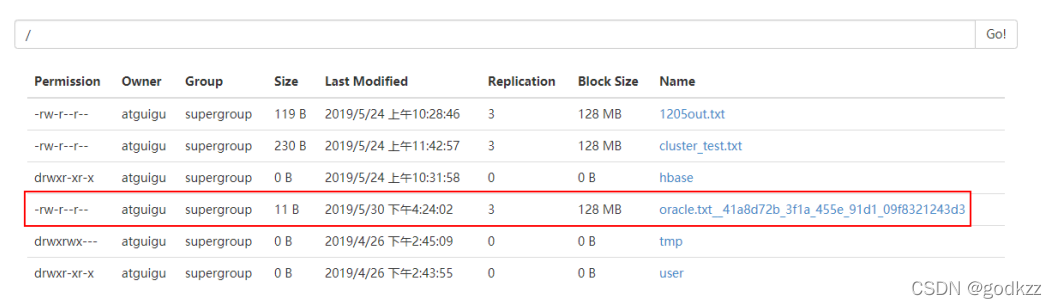
————————————————
版权声明:本文为CSDN博主「godkzz」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/godkzz/article/details/122306514