
一、前言
最近几天在开发公司业务时,遇到了需要往不数据库中多个表中插入大量数据的一个场景,于是有了这篇文章:
在使用Mybatis批量插入数据时的注意事项,以及使用函数式编程对分批次数据插入方法的简单封装。
对于包含我在内大部分Java后端开发的小伙伴们在平常的CURD开发工作中,一定是免不了使用Mybatis这个工具来对数据库进行操作的。
在SpringBoot的工程中,引入Mybatis后,可使用mapper注入的方式来实现增删改查。
比如如果要新增一条数据,那么在mapper.xml文件中可以这么写:
<insert id="testInsert">
insert into massive_data_insert_test
(value1,value2)
values
(#{value1},#{value2})
</insert>
然后在service层调用mapper.insertOneItem(insertItem);即可。
如果要新增多条数据,如果是刚学Java的同学可能会这么写:
for(int i = 0; i < insertList.size(); i++){
mapper.insertOneItem(insertList.get(i));
}
就是简单的放在一个循环中,多次调用mapper中的数据库新增方法。这种方法编写简单易于理解,在数据量比较少的时候是不会有什么问题的。
但是一旦数据过多就会有问题了。
实际上每次的mapper方法调用都是一次连接数据库、预处理(PreparedStatement)、execute(执行SQL)的过程。
由此发现,如果放在for循环中的话,上述过程则会多次执行,而我们又清楚数据库的连接数是有限的(建立连接的过程也是很耗费资源的),如果for循环的次数过多时,不仅性能会下降还会造成数据库的堵塞甚至程序崩溃。当然,我们可以创建或配置数据库连接池(比如HikariCP、Durid等)来复用连接,但这还是对资源的一种浪费。
总而言之,如果能有一种方法来一次性把要完成的事情做完就不要分多次去做。
大部分数据库的新增语句是支持一次插入多条数据的。
insert into table
(value1, value2)
values ('v1','v2'),('v3','v4'),('v1','v5')
Mybatis也给出了一种批量操作数据的方法。使用动态SQL语句中的<foreach>标签,将帮助我们拼接出形似上面的SQL语句。
我们在mapper.xml中编写下面的内容:
<insert id="testMassiveInsert">
insert into massive_data_insert_test
(value1,value2)
values
<foreach collection="list" item="item" separator=",">
(#{item.value1},#{item.value2})
</foreach>
</insert>
这样我们就只需要调用一次mapper中的方法就能达到上面for循环代码的效果。
并且实际上执行的时候也是执行一次SQL,这个动态SQL语句的作用就是将传入的参数的内容拼接到插入语句的SQL中(预处理技术)。
这种方法很明显要比一开始的for循环的实现要好一点了。
二、批量插入数据量达到上万后报错
但是,当我们用上述的拼接SQL的方式进行批量插入时,数据量过大也会出现问题!
我们可以先来实验一下批量插入一个四万条数据会怎样。
先来新建一张表作为插入数据的目标表:massive_data_insert_test。
CREATE TABLE "supply"."massive_data_insert_test" (
"value1" varchar(255) COLLATE "pg_catalog"."default",
"value2" varchar(255) COLLATE "pg_catalog"."default"
);
随便在一个SpringBoot的工程中连接数据库并创建mapper,编写插入语句(创建工程和扫描mapper等操作就不在此赘述了):
下面是mapper接口和mapper.xml文件(中的sql语句)。
TestMapper.java
@Repository
public interface TestMapper.java {
void testMassiveInsert(List<HashMap> list);
}
TestMapper.xml
<insert id="testMassiveInsert">
insert into massive_data_insert_test
(value1,value2)
values
<foreach collection="list" item="item" separator=",">
(#{item.value1},#{item.value2})
</foreach>
</insert>
测试语句:
@Service
@Slf4j
public class TestService {
// 批量新增的最大数量
private static final int maxInsertItemNumPerTime = 500;
private TestMapper mapper;
@Autowired
public TestService(TestMapper mapper) {
this.mapper = mapper;
}
public Result testMassiveInsert() {
long startTime = System.currentTimeMillis(); //获取开始时间
List<HashMap> list = new LinkedList<>();
// 组装数据 获得一个长度为 500 * 80 = 40000的链表
for (int i = 0; i < maxInsertItemNumPerTime * 80; i++) {
HashMap map = new HashMap();
map.put("value1", "value1" + i);
map.put("value2", "value2" + i);
list.add(map);
}
// 直接批量插入
try {
mapper.testMassiveInsert(list);
} catch (RuntimeException e) {
log.info("直接批量插入" + list.size() + "失败", e.getMessage());
throw new RuntimeException(e);
}
long endTime = System.currentTimeMillis(); //获取结束时间
return Result.ok().message("程序运行时间:" + (endTime - startTime) + "ms");
}
}
当执行上面的直接批量插入时:
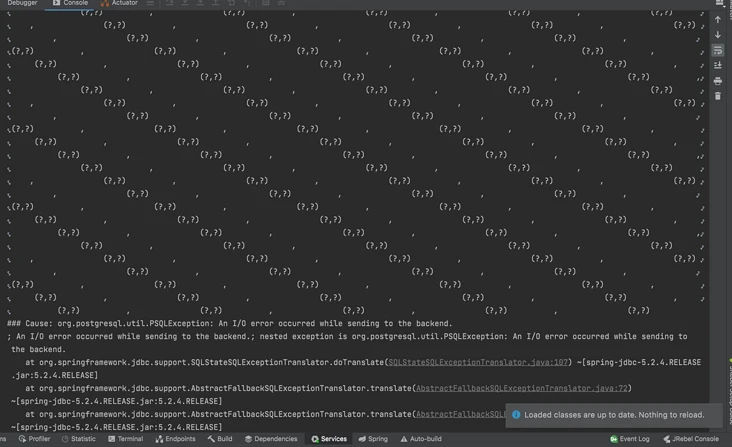
直接报出了I/O error,为什么会这样呢?
在前文中提到过这个动态SQL语句的作用就是将传入的参数的内容拼接到插入语句的SQL中,所以发生这个错误的原因就是因为要拼接的内容过多,导致SQL语句过长从而导致了I/O的错误。所以当数据量过大时就会使得拼接过长从而导致程序报错。
并且这个SQL的长度不光跟数据量有关,还跟插入语句的插入参数的数量有关。实际上,SQL的长度与二者的乘积呈正相关的线性变化,所以当插入参数过多时更要控制好批量插入数据量的大小。
那么怎么解决呢?最简单的就是分批次插入了,这有点像文章一开始提到的for循环中依次插入的方式,只不过是这回for循环中的插入是批量插入了。
由于不是一次性的插入,所以需要加上事务的包裹,从而保证无论哪次插入出错都能回滚。
@Transactional
public Result testMassiveInsert() {
long startTime = System.currentTimeMillis(); //获取开始时间
List<HashMap> list = new LinkedList<>();
// 组装数据 获得一个长度为 500 * 80 = 40000的链表
for (int i = 0; i < maxInsertItemNumPerTime * 80; i++) {
HashMap map = new HashMap();
map.put("value1", "value1" + i);
map.put("value2", "value2" + i);
list.add(map);
}
// 分批次的批量插入
try {
if (list.size() > maxInsertItemNumPerTime) {
List<List<HashMap>> all = new ArrayList<>();
int i = 0;
while (i < list.size()) {
List subList = list.subList(i, i + maxInsertItemNumPerTime);
i = i + maxInsertItemNumPerTime;
all.add(subList);
}
all.parallelStream().forEach(o -> mapper.testMassiveInsert(o));
}
} catch (RuntimeException e) {
log.info("分批次批量插入" + list.size() + "失败", e.getMessage());
throw new RuntimeException(e);
}
long endTime = System.currentTimeMillis(); //获取结束时间
return Result.ok().message("程序运行时间:" + (endTime - startTime) + "ms");
}
我们通过设置一个maxInsertItemNumPerTime来控制每次批量插入数据的长度。
三、简单测试
下面我的简单测试(即插入总数量为4w条,但设置不同maxInsertItemNumPerTime大小时,计算比较程序运行的耗时)。不过该测试没有进行很多次测试取平均并又可能网络也有抖动,所以只能算是简单测试。
- 2000
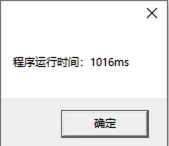
- 1000
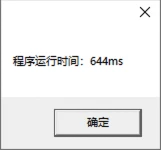
- 500
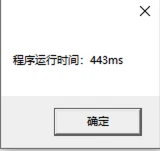
- 250
-
最后我选择了500作为分批次插入时每个批次的大小。正如我们上文所说的一样,即使有数据库连接池提供的连接复用,但是如果跟数据库的交互多了还是会造成性能的下降,所以这里的
maxInsertItemNumPerTime的也不是越小越好。同时,随着
maxInsertItemNumPerTime的变大,每一次for循环中的SQL的预处理过程(SQL拼接)耗时会变大,并且这种变大并不是一种线性的,而是往往呈现指数型变大(查了一些资料证实了我的这个猜测),否则的话就不会是2000的时候要远远大于500了。大家在实际业务中也需要简单测测来选取一个比较合适的值,总比没有测试的要好。
四、做点扩展
其实在Mybatis的官方文档中是提供了另外一种方式来支持批量插入的。
但由于公司的项目中都是用的扫描Mapper的方式来操作数据库,加上这种大数据插入场景确实比较少,所以就没有特意引进下面Mybatis提供的方式。
A multiple row insert is a single insert statement that inserts multiple rows into a table. This can be a convenient way to insert a few rows into a table, but it has some limitations:
- Since it is a single SQL statement, you could generate quite a lot of prepared statement parameters. For example, suppose you wanted to insert 1000 records into a table, and each record had 5 fields. With a multiple row insert you would generate a SQL statement with 5000 parameters. There are limits to the number of parameters allowed in a JDBC prepared statement – and this kind of insert could easily exceed those limits. If you want to insert many records, you should probably use a JDBC batch insert instead (see below)
- The performance of a giant insert statement may be less than you expect. If you have many records to insert, it will almost always be more efficient to use a JDBC batch insert (see below). With a batch insert, the JDBC driver can do some optimization that is not possible with a single large statement
- Retrieving generated values with multiple row inserts can be a challenge. MyBatis currently has some limitations related to retrieving generated keys in multiple row inserts that require special considerations (see below)
Nevertheless, there are use cases for a multiple row insert – especially when you just want to insert a few records in a table and don’t need to retrieve generated keys. In those situations, a multiple row insert will be an easy solution.
翻译:
try (SqlSession session = sqlSessionFactory.openSession()) { GeneratedAlwaysAnnotatedMapper mapper = session.getMapper(GeneratedAlwaysAnnotatedMapper.class); List<GeneratedAlwaysRecord> records = getRecordsToInsert(); // not shown MultiRowInsertStatementProvider<GeneratedAlwaysRecord> multiRowInsert = insertMultiple(records) .into(generatedAlways) .map(id).toProperty("id") .map(firstName).toProperty("firstName") .map(lastName).toProperty("lastName") .build() .render(RenderingStrategies.MYBATIS3); int rows = mapper.insertMultiple(multiRowInsert); }上面就是文档中的示例代码。
五、进一步优化代码
由于我在公司实际开发中要做的是要往多张表中导入数据,如果按照上面的分批次的写法的话,那我的每一次插入都要有这么一段逻辑:
// 分批次的批量插入 try { if (list.size() > maxInsertItemNumPerTime) { List<List<HashMap>> all = new ArrayList<>(); int i = 0; while (i < list.size()) { List subList = list.subList(i, i + maxInsertItemNumPerTime); i = i + maxInsertItemNumPerTime; all.add(subList); } all.parallelStream().forEach(o -> mapper.testMassiveInsert(o)); } } catch (RuntimeException e) { log.info("分批次批量插入" + list.size() + "失败", e.getMessage()); throw new RuntimeException(e); }显然这有点重复代码的坏味道了,看起来就很不好。所以接下来做个简单封装,将这段代码封装到一个方法中,谁插入时就由谁调用。
首先,这段代码需要传入的参数是什么?
maxInsertItemNumPerTime不需要传入,因为显然这是一个常量list插入的内容链表,需要传入,并且类型不会全都是HashMap,而是不同表对应不同的实体类。需要用到泛型T。mapper中的testMassiveInsert(HashMap map)方法,很明显不同表的插入mapper肯定不是同一个方法,所以这个也需要传入,把一个方法当作参数传入,那么就需要用到Lambda表达式和函数式编程。如果你了解过函数式接口,你很自然就会想到像这种只有输入没有输出的函数应该由Consumer来传入(反之对应Supplier,有输入又有输出时则是Function)。
所以最后抽象出的代码应该是这样的:
public <T> void batchSplitInsert(List<T> list, Consumer insertFunc) { List<List<T>> all = new ArrayList<>(); if (list.size() > maxInsertItemNumPerTime) { int i = 0; while (i < list.size()) { if (i + maxInsertItemNumPerTime > list.size()){ subList = list.subList(i, list.size()); }else { subList = list.subList(i, i + maxInsertItemNumPerTime); } i = i + maxInsertItemNumPerTime; all.add(subList); } all.parallelStream().forEach(insertFunc); } else { insertFunc.accept(list); } }这样子我在做不同表的插入时:
// 待插入数据链表 List<TableDTO> needToInsert = ……; // 进行新增 Consumer<List<TableDTO>> consumer = o -> mapper.insertTable(o); batchSplitInsert(needToInsert, consumer);现在整个世界都变优雅了!如果刚入职或者刚学
Java的小伙伴还对函数式编程不了解,不如先从从简单的Lambda语句开始学起,这个真的是Java8中超好用的一个特性。到此为止,本文就算是结束了,大家有啥疑问,请评论留言,咱们相互交流。
转自:https://segmentfault.com/a/1190000041216368
- 250

