rollup函数
本博客简单介绍一下oracle分组函数之rollup的用法,rollup函数常用于分组统计,也是属于oracle分析函数的一种
环境准备
create table dept as select * from scott.dept;
create table emp as select * from scott.emp;
业务场景:求各部门的工资总和及其所有部门的工资总和
这里可以用union来做,先按部门统计工资之和,然后在统计全部部门的工资之和
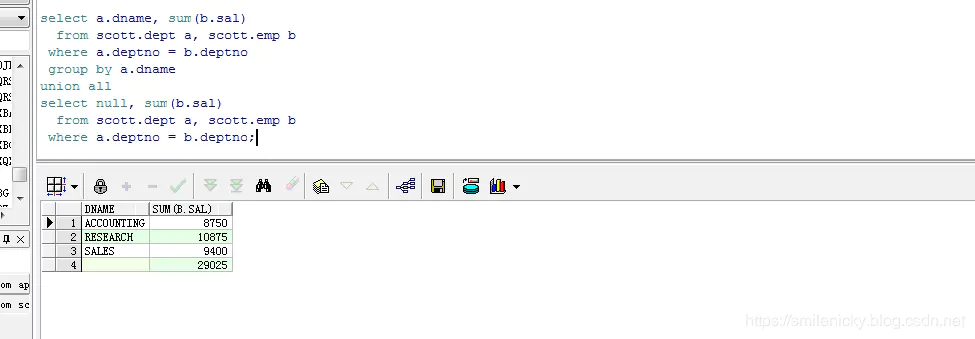
select a.dname, sum(b.sal)
from scott.dept a, scott.emp b
where a.deptno = b.deptno
group by a.dname
union all
select null, sum(b.sal)
from scott.dept a, scott.emp b
where a.deptno = b.deptno;
上面是用union来做,然后用rollup来做,语法更简单,而且性能更好
select a.dname, sum(b.sal)
from scott.dept a, scott.emp b
where a.deptno = b.deptno
group by rollup(a.dname);
业务场景:基于上面的统计,再加需求,现在要看看每个部门岗位对应的工资之和
select a.dname, b.job, sum(b.sal)
from scott.dept a, scott.emp b
where a.deptno = b.deptno
group by a.dname, b.job
union all//各部门的工资之和
select a.dname, null, sum(b.sal)
from scott.dept a, scott.emp b
where a.deptno = b.deptno
group by a.dname
union all//所有部门工资之和
select null, null, sum(b.sal)
from scott.dept a, scott.emp b
where a.deptno = b.deptno;
用rollup实现,语法更简单
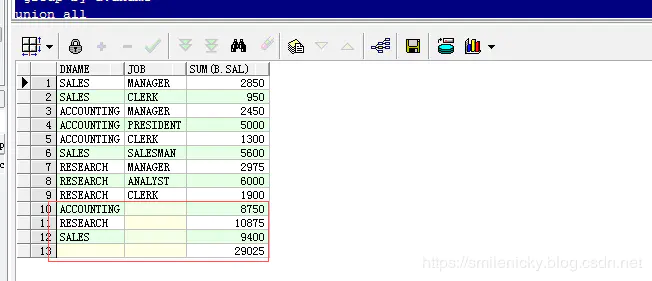
select a.dname, b.job, sum(b.sal)
from scott.dept a, scott.emp b
where a.deptno = b.deptno
group by rollup(a.dname, b.job);
假如再加个时间统计的,可以用下面sql:
select to_char(b.hiredate, 'yyyy') hiredate, a.dname, b.job, sum(b.sal)
from scott.dept a, scott.emp b
where a.deptno = b.deptno
group by rollup(to_char(b.hiredate, 'yyyy'), a.dname, b.job);
cube函数
select a.dname, b.job, sum(b.sal)
from scott.dept a, scott.emp b
where a.deptno = b.deptno
group by cube(a.dname, b.job);
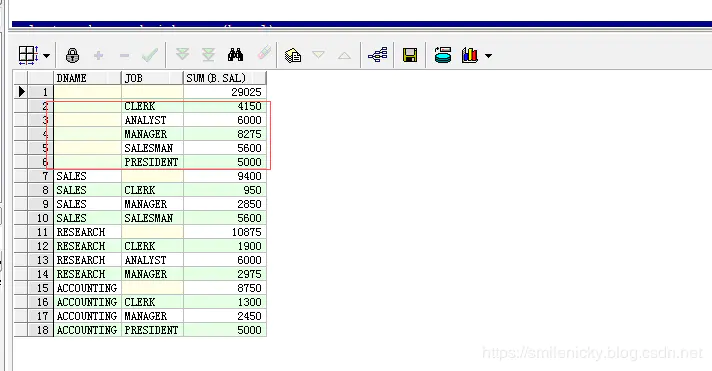
cube函数是维度更细的统计,语法和rollup类似
假设有n个维度,那么rollup会有n个聚合,cube会有2n个聚合
-
rollup统计列
rollup(a,b) 统计列包含:(a,b)、(a)、()
rollup(a,b,c) 统计列包含:(a,b,c)、(a,b)、(a)、()
…. -
cube统计列
cube(a,b) 统计列包含:(a,b)、(a)、(b)、()
cube(a,b,c) 统计列包含:(a,b,c)、(a,b)、(a,c)、(b,c)、(a)、(b)、(c)、()
转自:https://www.jianshu.com/p/a6316514c1f9