1.ShardingSphere
sharding-jdbc后续发展为Sharding-Sphere,包含sharding-jdbc、Sharding-Proxy、Sharding-Sidecar。
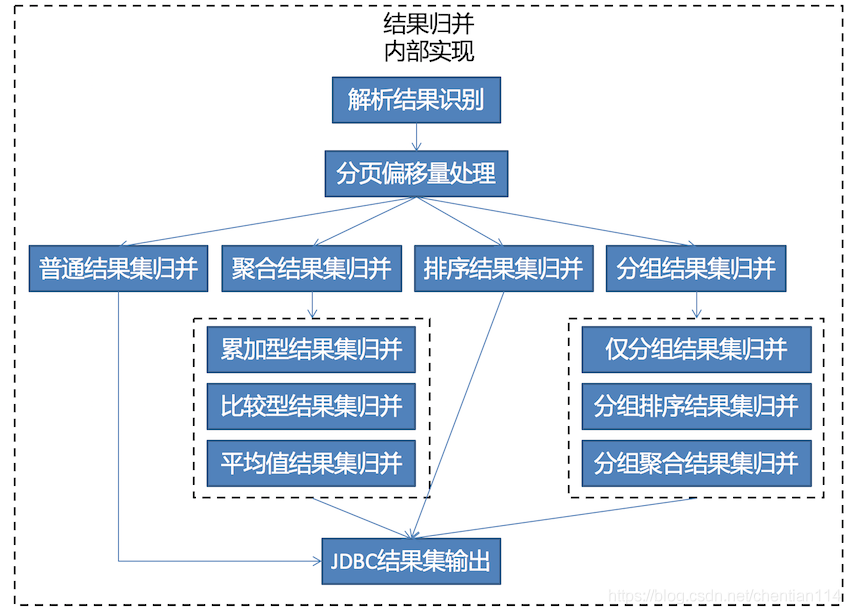
1)概述:ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景。
2)定位:ShardingSphere定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。
2.Sharding-JDBC
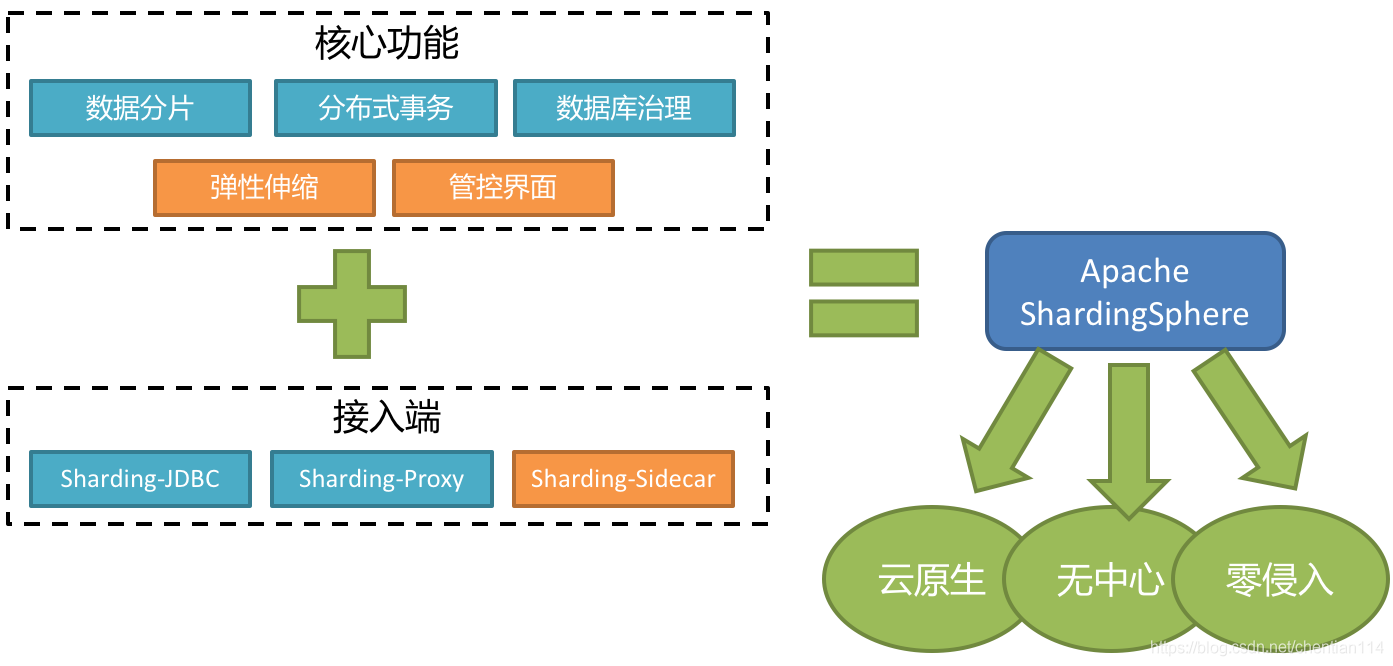
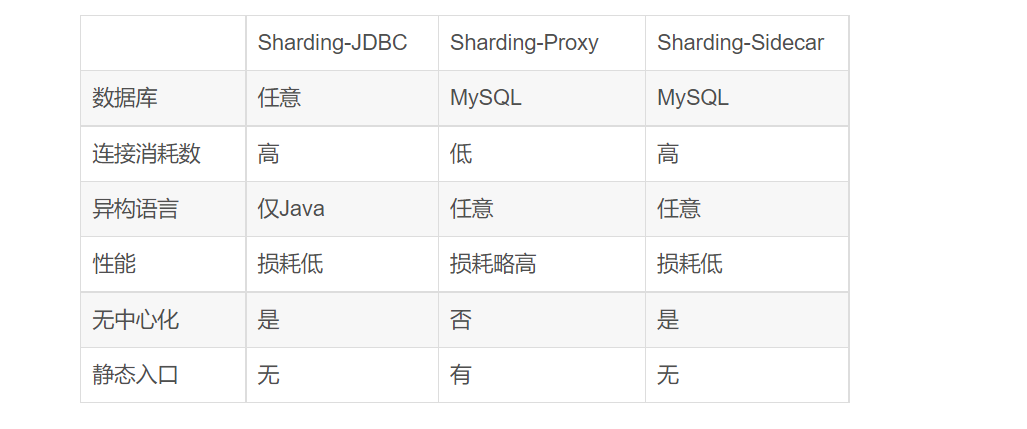
定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
1)适用于任何基于Java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
2)基于任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
3)支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer和PostgreSQL。
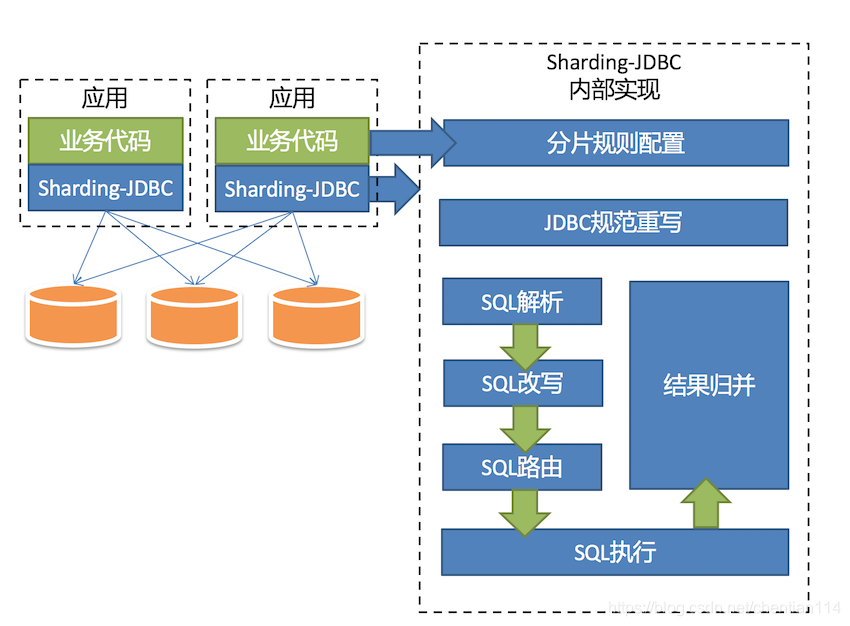
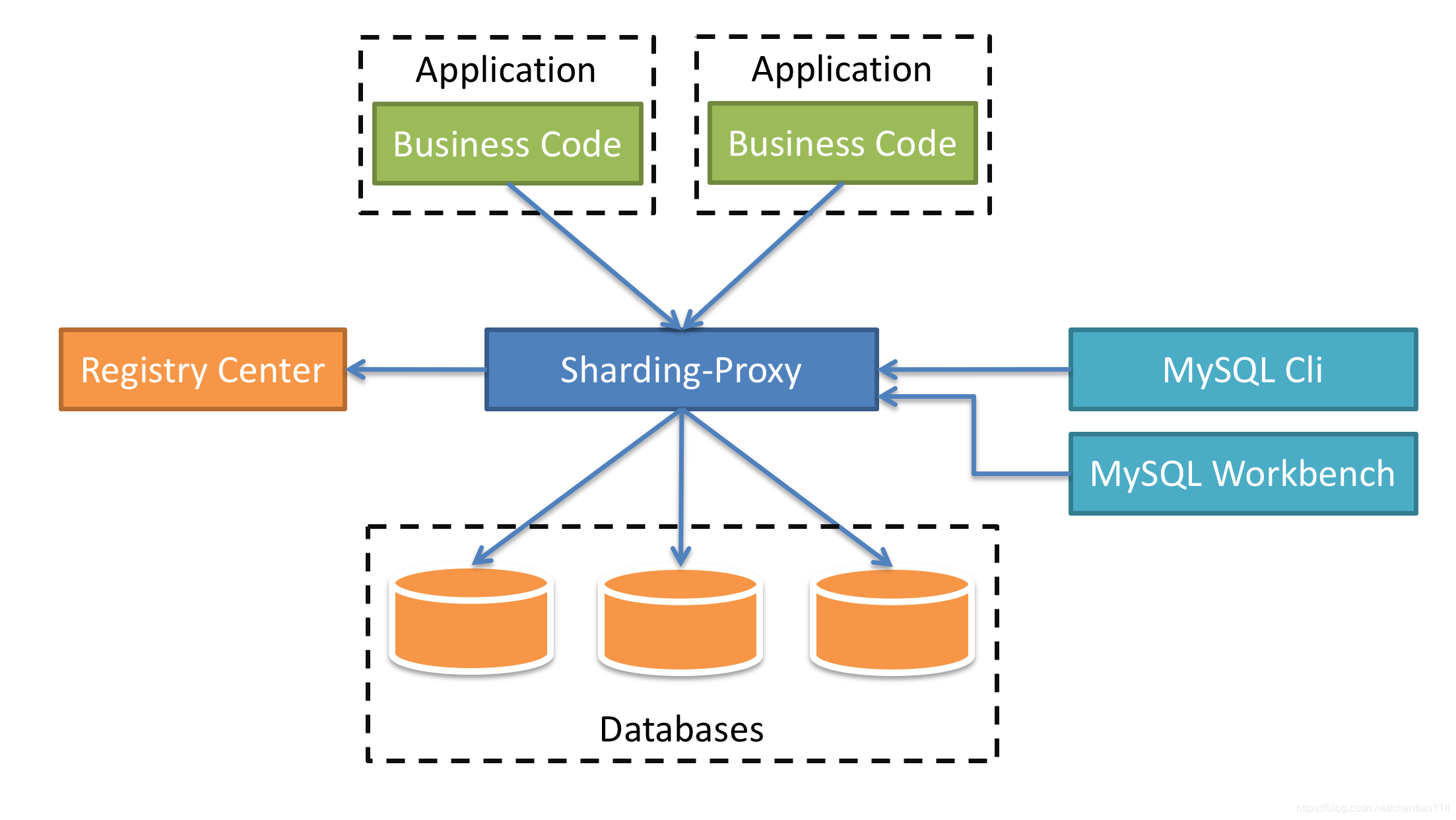
3.Sharding-Proxy
定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。
目前先提供MySQL版本,它可以使用任何兼容MySQL协议的访问客户端(如:MySQL Command Client, MySQL Workbench等)操作数据,对DBA更加友好。
1)向应用程序完全透明,可直接当做MySQL使用。
2)适用于任何兼容MySQL协议的客户端。
4.Sharding-Sidecar(TBD)
定位为Kubernetes或Mesos的云原生数据库代理,以DaemonSet的形式代理所有对数据库的访问。 通过无中心、零侵入的方案提供与数据库交互的的啮合层,即Database Mesh,又可称数据网格。
Database Mesh的关注重点在于如何将分布式的数据访问应用与数据库有机串联起来,它更加关注的是交互,是将杂乱无章的应用与数据库之间的交互有效的梳理。
使用Database Mesh,访问数据库的应用和数据库终将形成一个巨大的网格体系,应用和数据库只需在网格体系中对号入座即可,它们都是被啮合层所治理的对象。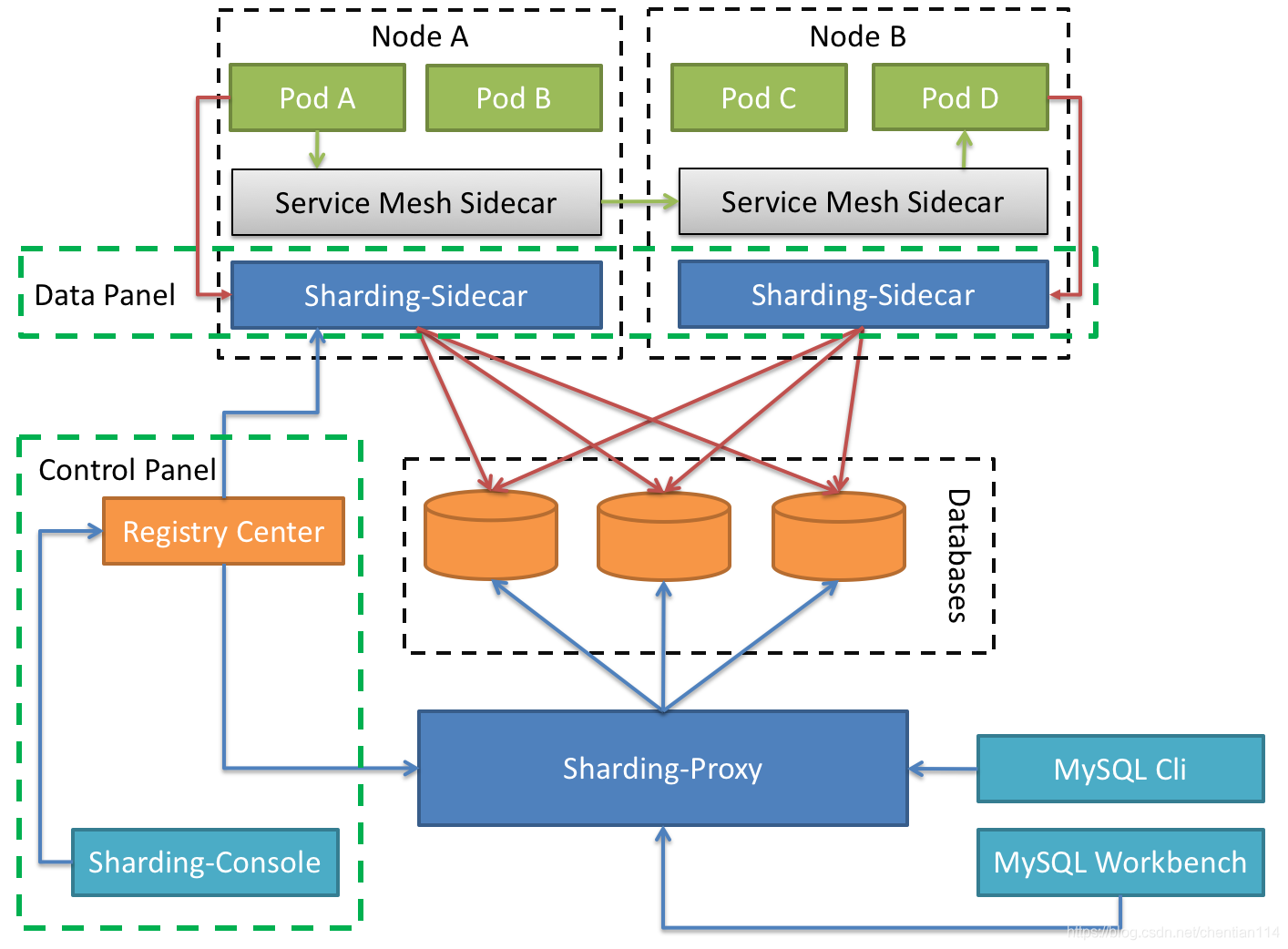
5.Sharding-JDBC包含的一些核心概念:
1)LogicTable。
数据分片的逻辑表,对于水平拆分的数据库(表),同一类表的总称。例:订单数据根据主键尾数拆分为10张表,分别是t_order_0到t_order_9,他们的逻辑表名为t_order。
2)ActualTable。
在分片的数据库中真实存在的物理表。即上个示例中的t_order_0到t_order_9。
3)DataNode。
数据分片的最小单元。由数据源名称和数据表组成,例:ds_1.t_order_0。配置时默认各个分片数据库的表结构均相同,直接配置逻辑表和真实表对应关系即可。如果各数据库的表结果不同,可使用ds.actual_table配置。
4)DynamicTable。
逻辑表和真实表不一定需要在配置规则中静态配置。比如按照日期分片的场景,真实表的名称随着时间的推移会产生变化。此类需求Sharding-JDBC是支持的,不过目前配置并不友好,会在新版本中提升。
5)BindingTable。
指在任何场景下分片规则均一致的主表和子表。例:订单表和订单项表,均按照订单ID分片,则此两张表互为BindingTable关系。BindingTable关系的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。
6)ShardingColumn。
分片字段。用于将数据库(表)水平拆分的关键字段。例:订单表订单ID分片尾数取模分片,则订单ID为分片字段。SQL中如果无分片字段,将执行全路由,性能较差。Sharding-JDBC支持多分片字段。
7)ShardingAlgorithm。
分片算法。Sharding-JDBC通过分片算法将数据分片,支持通过等号、BETWEEN和IN分片。分片算法目前需要业务方开发者自行实现,可实现的灵活度非常高。未来Sharding-JDBC也将会实现常用分片算法,如range,hash和tag等。
8)SQL Hint。
对于分片字段非SQL决定,而由其他外置条件决定的场景,可使用SQL Hint灵活的注入分片字段。例:内部系统,按照员工登录ID分库,而数据库中并无此字段。SQL Hint支持通过ThreadLocal和SQL注释(待实现)两种方式使用。
6.分布式数据库中间件、产品——sharding-jdbc、mycat、drds比较
1)原因:一般对于业务记录类随时间会不断增加的数据,当数据量增加到一定量(一般认为整型值为主的表达到千万级,字符串为主的表达到五百万)的时候,性能将遇到瓶颈,同时调整表结构也会变得非常困难。为了避免生产遇到这样的问题,在做系统设计时需要预估可能产生的数据量:预估记录主体个数*预估记录主体产生的记录数(用户订单表预估数据量=预估用户数*单用户产生订单数),预估达到一定量时,就不得不考虑分库分表了。
2)选择:目前国内比较成熟的开源数据库中间件有:sharding-jdbc、mycat;而drds是阿里云最近推出的商业产品,考虑到大部分公司都在使用阿里云,做一个全家桶,也是一个不错的选择。
接下来将对这三款产品的优缺点及适用场景做以介绍。
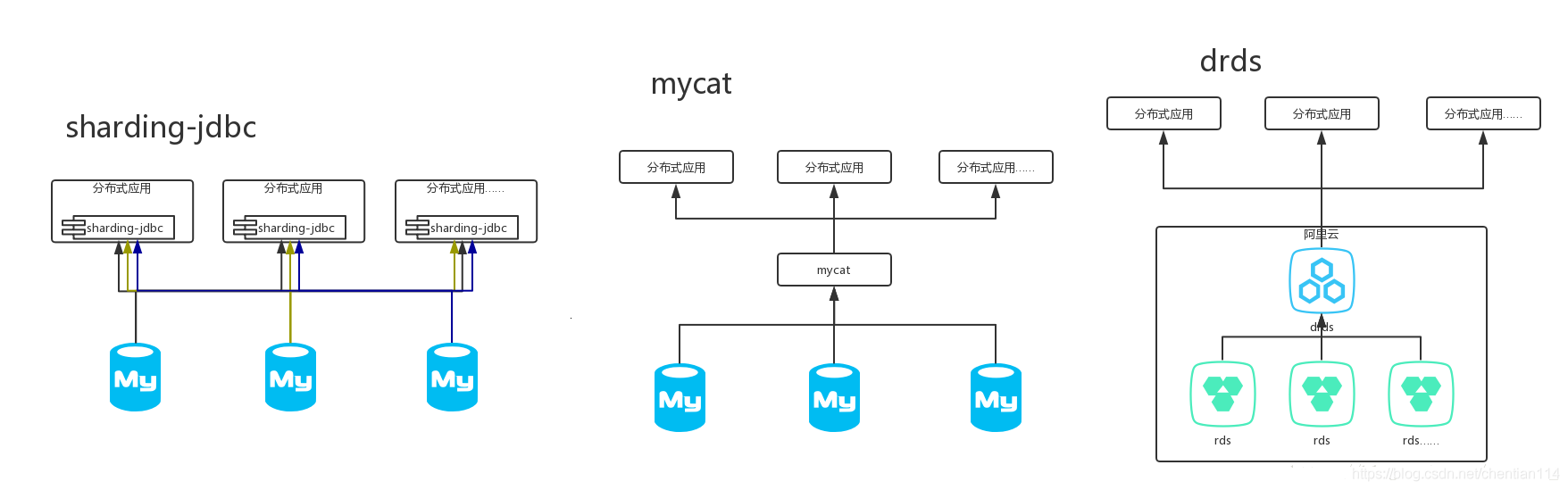
3)使用方式:sharding-jdbc作为一个组件集成在应用内,而mycat则作为一个独立的应用需要单独部署,drds则是阿里云的一个独立产品,不过需要结合rds一起使用。
4)sharding-jdbc
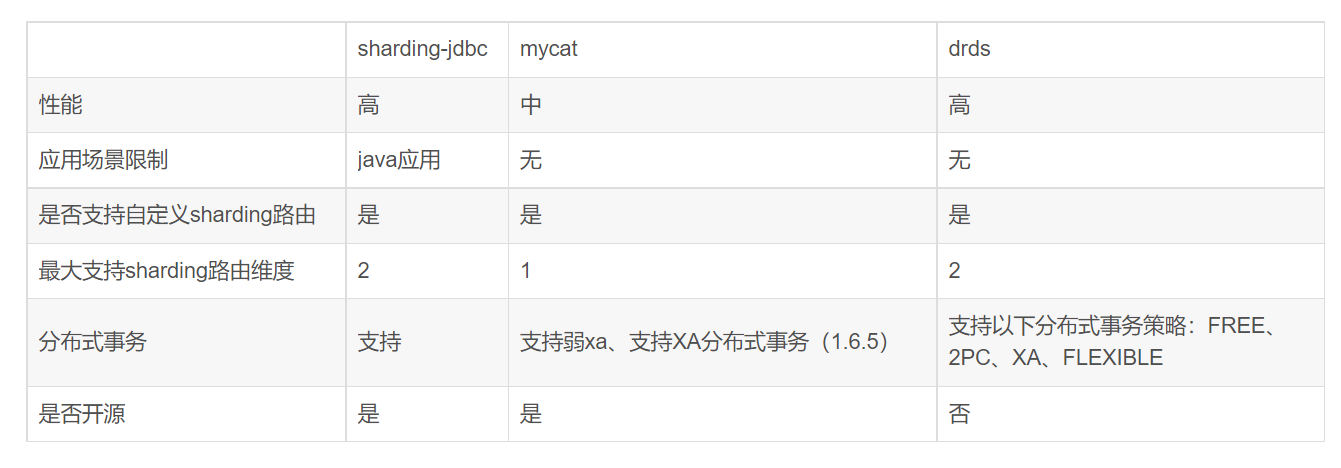
优点:1.理论性能最高。从架构上看sharding-jdbc更符合分布式架构的设计,直连数据库,没有中间应用,理论性能是最高的(实际性能需要结合具体的代码实现,理论性能可以理解为上限,通过不断优化代码实现,逐渐接近理论性能)。
缺点:1.开发成本相对较高。由于作为组件存在,需要集成在应用内,意味着作为使用方,必须要集成到代码里,使得开发成本相对较高;2.开发场景限定为Java。由于需要集成在应用内,使得需要针对不同语言有不同的实现,事实上sharding-jdbc目前只支持java,这样组件本身的维护成本也会很高。
5)mycat
mycat是支持SQL92标准,遵守Mysql原生协议,跨语言,跨平台,跨数据库的通用中间件代理。
优点:作为对比可以参考上表中的Sharding-Proxy,需要单独部署,由于遵守Mysql原生协议,应用时不需要特殊处理,和使用MySQL是一样的,所以应用场景不受限制;
缺点:需要维护自身的连接池。但是mycat不支持二维路由,仅支持单库多表或多库单表,同时由于自定义连接池,这样就会存在mycat自身维护一个连接池,MySQL也有一个连接池,任何一个连接池上限都会成为性能的瓶颈,而mycat的连接池设计也略显粗暴,当请求链接数大于设置连接池上限时直接抛出异常,因此在配置mycat连接池的大小是,需要结合场景做合理设置。
总的来说,mycat以逻辑表的形式屏蔽掉应用处理分库分表的复杂逻辑,遵守Mysql原生协议,跨语言,跨平台,有着更为通用的应用场景。
6)DRDS
DRDS 兼容 MySQL 协议和语法,支持分库分表、平滑扩容、服务升降配、透明读写分离和分布式事务等特性,具备分布式数据库全生命周期的运维管控能力。
可以看成mycat的商业化产品,也就是mycat所有的优点它都有,而且作为一个商业化产品使用上更为简单透明,功能也更为丰富;如果不差钱而且正准备对数据做重构,那么drds是一个不错的选择,之所以说准备做数据重构时考虑用drds,是因为drds不是一个简单的做sharding路由,即使原来使用的是rds,也无法通过drds做路由,唯一的办法新建drds实例,定义路由规则(drds支持二维路由),导入历史数据,然后就可以开心的使用drds了。
7.sharding-jdbc详细实现