-
横向分区:例如一张表有100万条数据,可以分成十份,第一份10万条数据放到第一个分区,第二份10万条数据放到第二个分区,依此类推。也就是把表分成了十份,与水平分表类似。在取出一条数据时,这条数据包含了表结构中的所有字段,也就是说横向分区并没有改变表的结构。 -
纵向分区:例如在设计用户表的时候,起初没有考虑周全,把个人的所有信息都放到了一张表中,这样表中就会有比较大的字段,例如个人简介,而这些简介可能不需要经常用到,应该在需要用到时再去查询,可以利用纵向分区将大字段对应的数据进行分块存放,从而提高磁盘IO,与垂直分表类似。从MySQL横向分区和纵向分区的原理来看,这与MySQL水平分表和垂直分表类似,但它们是有区别的,分表注重的是存取数据时如何提高MySQL的并发能力,而分区注重的是如何突破磁盘的IO能力,从而达到提高MySQL性能的目的。分表会把一张数据表真正地拆分为多个表,而分区是把表的数据文件和索引文件进行分割,达到分而治之的效果。
-
性能的提升(Increased performance) :在扫描操作中,如果MySQL的优化器知道哪个分区中才包含特定查询中需要的数据,它就能直接去扫描那些分区的数据,而不用浪费很多时间扫描不需要的地方了。
-
2)对数据管理的简化(Simplified data management):- 分区技术可以让DBA对数据的管理能力提升。通过优良的MySQL数据库分区,DBA可以简化特定数据操作的执行方式。例如:DBA在对某些分区的内容进行删除的同时能保证余下的分区的数据完整性(这是跟对表的数据删除这种大动作做比较的)。此外分区是由MySQL系统直接管理的,DBA不需要手工的去划分和维护。例如:这个例如没意思,不讲了,如果你是DBA,只要你划分了分区,以后你就不用管了就是了。
-
RANGE分区:基于属于一个给定连续区间的列值,把多行分配给分区。 -
LIST分区:类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择。 -
HASH分区:基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含MySQL 中有效的、产生非负整数值的任何表达式。 -
KEY分区:类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL 服务器提供其自身的哈希函数。必须有一列或多列包含整数值。
RANGE分区是最常用的分区,它基于一个给定连续区间的列值,把多行分配给分区。这些区间要连续且不能相互重叠,使用VALUES LESS THAN操作符来进行定义。
1.1 创建分区表 ids_member
CREATE TABLE ids_member (id int not NULL PRIMARY KEY auto_increment,username VARCHAR(50) NOT NULL,gender VARCHAR(1) ) PARTITION BY RANGE (id) (PARTITION p1 VALUES less than (50),PARTITION p2 VALUES less than (100),PARTITION p3 VALUES less than (150),PARTITION p4 VALUES less than (200),PARTITION p5VALUES less than (250));
1.2 向分区表插入 160条数据
insert into ids_member(username)values('test')
1.3查看下分区下各自含有几条数据
SELECT partition_name part,partition_expression expr,partition_description descr,table_rows FROM information_schema.`PARTITIONS`WHERE table_schema=SCHEMA() AND table_name='ids_member';
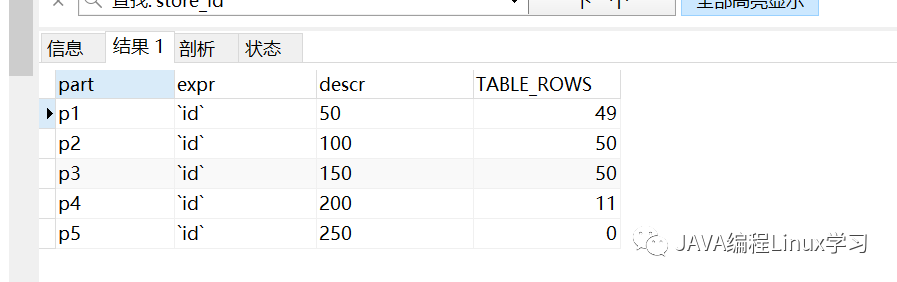
1.4 为了证明p1寸的id是1-49我们删除p1分区
ALTER TABLE ids_member DROP PARTITION p1
查询ids_member 表发现id为1-49的用户已被删除
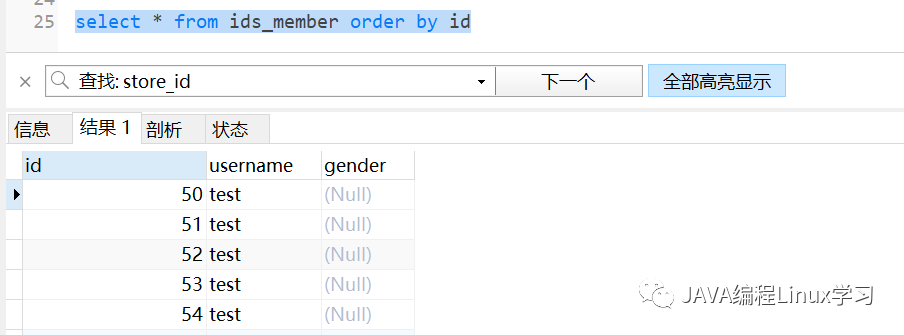
按照这种分区方案,在用户id为1到49的员工对应的所有行被保存在分区P0中,用户id50到99的员工保存在P1中,依次类推。
2. LIST分区
类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择。LIST分区通过使用“PARTITION BY LIST(expr)”来实现,其中“expr”是某列值或一个基于某个列值、并返回一个整数值的表达式,然后通过“VALUES IN (value_list)”的方式来定义每个分区,其中“value_list”是一个通过逗号分隔的整数列表。
2.1 创建分区表
CREATE TABLE ids_member_list (id int not NULL PRIMARY KEY auto_increment,username VARCHAR(50) NOT NULL,gender VARCHAR(1) ) partition by list(id)( partition pl1 values in (1,3,5,7,9), partition pl2 values in (2,4,6,8,10));
2.2 向分区表插入 10条数据
insert into ids_member_list(username)values('test')
2.3查看下分区下各自含有几条数据
SELECT partition_name part,partition_expression expr,partition_description descr,table_rows FROM information_schema.`PARTITIONS`WHERE table_schema=SCHEMA() AND table_name='ids_member_list';
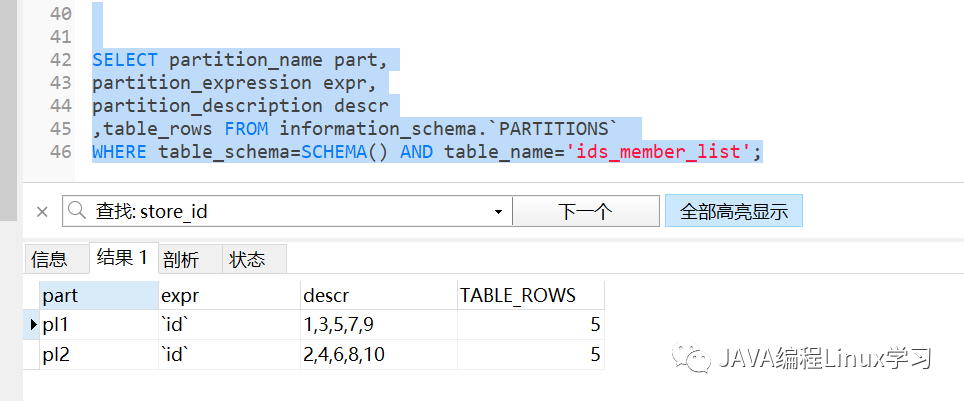
2.4 删除分区pl1
ALTER TABLE ids_member_list DROP PARTITION pl2
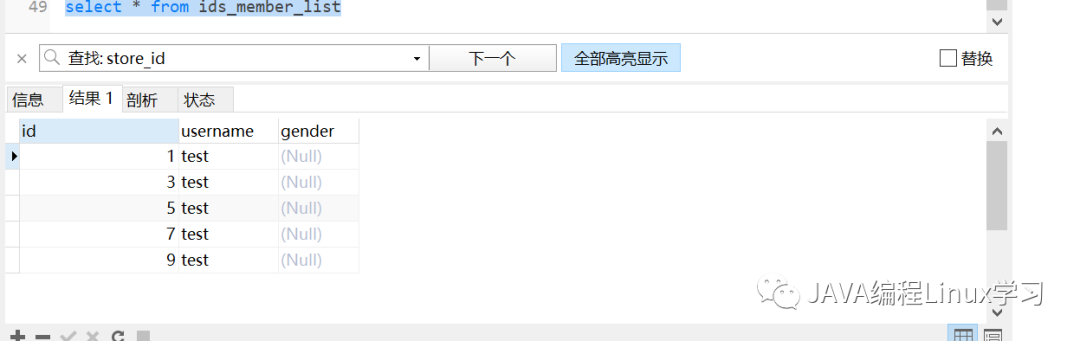
执行查询可见仅剩id为1、 3、 5、 7、 9的数据
select * from ids_member_list
3. HASH分区
基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含MySQL 中有效的、产生非负整数值的任何表达式。要使用HASH分区来分割一个表,要在CREATE TABLE 语句上添加一个“PARTITION BY HASH (expr)”子句,其中“expr”是一个返回一个整数的表达式。它可以仅仅是字段类型为MySQL 整型的一列的名字。此外,你很可能需要在后面再添加一个“PARTITIONS num”子句,其中num 是一个非负的整数,它表示表将要被分割成分区的数量。
3.1创建HASH分区表ids_member_hash
CREATE TABLE ids_member_hash (id int not NULL PRIMARY KEY auto_increment,username VARCHAR(50) NOT NULL,gender VARCHAR(1) ) partition by hash(id)partitions 4;
4、KSY分区
类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL 服务器提供其自身的哈希函数。必须有一列或多列包含整数值。
4.1创建KSY分区表
CREATE TABLE ids_member_key (id int not NULL PRIMARY KEY auto_increment,username VARCHAR(50) NOT NULL,gender VARCHAR(1) ) partition by linear key (id)partitions 3;
在KEY分区中使用关键字LINEAR和在HASH分区中使用具有同样的作用,分区的编号是通过2的幂(powers-of-two)算法得到,而不是通过模数算法。
表分区的基本操作
-
创建分区(以创建RANGE分区为例)
CREATE TABLE ids_member (id int not NULL PRIMARY KEY auto_increment,username VARCHAR(50) NOT NULL,gender VARCHAR(1) ) PARTITION BY RANGE (id) (PARTITION p1 VALUES less than (50),PARTITION p2 VALUES less than (100),PARTITION p3 VALUES less than (150),PARTITION p4 VALUES less than (200),PARTITION p5VALUES less than (250));
-
增加表分区
PARTITION p1 VALUES LESS THAN (MAXVALUE) 这句要去掉,才可以增加分区。ALTER TABLE shops_goods ADD PARTITION (PARTITION s20230512 VALUES LESS THAN (20230512));
-
删除表分区
ALTER TABLE shops_goods DROP PARTITION s20230511 ;
-
查看分区
SELECT partition_name part,partition_expression expr,partition_description descr,table_rows FROM information_schema.`PARTITIONS` WHERE table_schema=SCHEMA() AND table_name='ids_member';