
neo4j是图数据库
初识neo4j,首先我们要知道neo4j是图数据库。我们平常用的数据库一般是RDBMS(关系型数据库),那么什么是图数据库呢?既然有了关系型数据库,那么为什么要有图数据库呢?
1.什么是图数据库
简单来说:
图形数据库(图形数据库也称为图形数据库管理系统或GDBMS。
图数据库的基本含义是以“图”这种数据结构存储和查询数据,而不是存储图片的数据库。它的数据模型主要是以节点和关系(边)来体现,也可处理键值对。它的优点是快速解决复杂的关系问题。
数据结构:
在一个图中主要包含两种数据类型:Nodes(节点)和Relationships(关系)。他们各自内部又包含key-value形式的属性,然后节点之间通过关系相连,形成了关系型的网状结构
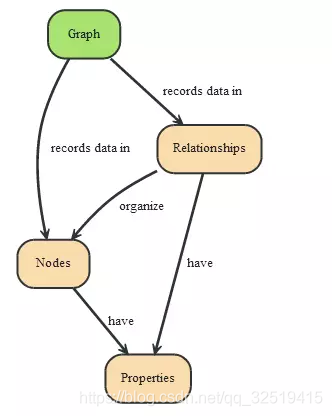
图数据库的应用
金融行业应用
反欺诈多维关联分析场景
通过图分析可以清楚地知道洗钱网络及相关嫌疑,例如对用户所使用的帐号、发生交易时的IP地址、MAC地址、手机IMEI号等进行关联分析。
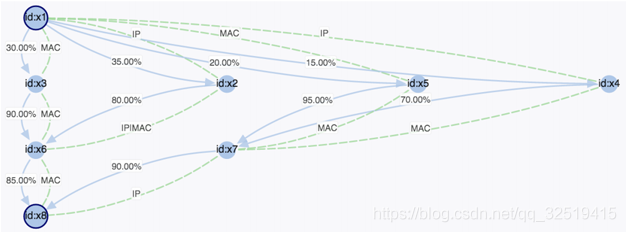
反欺诈多维关联分析场景
反欺诈已经是金融行业一个核心应用,通过图数据库可以对不同的个体、团体做关联分析,从人物在指定时间内的行为,例如去过地方的IP地址、曾经使用过的MAC地址(包括手机端、PC端、WIFI等)、社交网络的关联度分析,同一时间点是否曾经在同一地理位置附近出现过,银行账号之间是否有历史交易信息等。

社交网络图谱
在社交网络中,公司、员工、技能的信息,这些都是节点,它们之间的关系和朋友之间的关系都是边,在这里面图数据库可以做一些非常复杂的公司之间关系的查询。比如说公司到员工、员工到其他公司,从中找类似的公司、相似的公司,都可以在这个系统内完成。
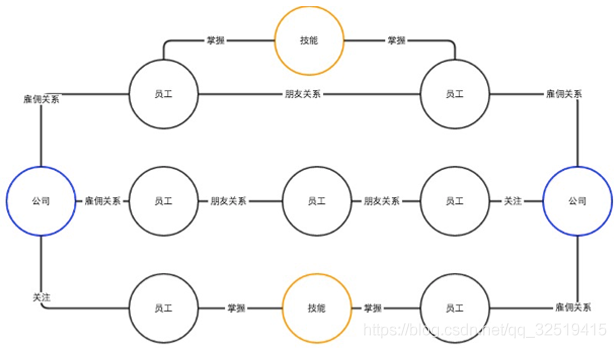
企业关系图谱
图数据库可以对各种企业进行信息图谱的建立,包括最基本的工商信息,包括何时注册、谁注册、注册资本、在何处办公、经营范围、高管架构。围绕企业的经营范围,继续细化去查询企业究竟有哪些产品或服务,例如通过企业名称查询到企业的自媒体,从而给予其更多关注和了解。另外也包括对企业的产品和服务的数据关联,查看该企业有没有令人信服的自主知识产权和相关资质来支撑业务的开展。
企业在日常经营中,与客户、合作伙伴、渠道方、投资者都会打交道,这也决定了企业对社会各个领域都广有涉猎,呈现面错综复杂,因此可以通过企业数据图谱来查询,层层挖掘信息。基于图数据的企业信息查询可以真正了解企业的方方面面,而不再是传统单一的工商信息查询。
2.什么是neo4j
Neo4j是一个高性能的NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。
它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络(从数学角度叫做图)上而不是表中。
Neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。程序员工作在一个面向对象的、灵活的网络结构下,而不是严格、静态的表中。但是他们可以享受到具备完全的事务特性、企业级的数据库的所有好处。
Neo4j因其嵌入式、高性能、轻量级等优势,越来越受到关注。
Neo4j的特点
SQL就像简单的查询语言Neo4j CQL
它遵循属性图数据模型
它通过使用Apache Lucence支持索引
它支持UNIQUE约束
它包含一个用于执行CQL命令的UI:Neo4j数据浏览器
它支持完整的ACID(原子性,一致性,隔离性和持久性)规则
它采用原生图形库与本地GPE(图形处理引擎)
它支持查询的数据导出到JSON和XLS格式
它提供了REST API,可以被任何编程语言(如Java,Spring,Scala等)访问
它提供了可以通过任何UI MVC框架(如Node JS)访问的Java脚本
它支持两种Java API:Cypher API和Native Java API来开发Java应用程序
Neo4j的优点
它很容易表示连接的数据
检索/遍历/导航更多的连接数据是非常容易和快速的
它非常容易地表示半结构化数据
Neo4j CQL查询语言命令是人性化的可读格式,非常容易学习
它使用简单而强大的数据模型
它不需要复杂的连接来检索连接的/相关的数据,因为它很容易检索它的相邻节点或关系细节没有连接或索引
Neo4j的缺点或限制
Neo4j 2.1.3最新版本,它具有支持节点数,关系和属性的限制。
它不支持Sharding。
下载地址
http://www.neo4j.org/download 根据操作系统和位数进行下载
基本使用
由于临时需要neo4j数据库,neo4j的安装和环境配置,以及过多的cql的语法就不去给大家说明了,大家可以参考w3cschool的教程
https://www.w3cschool.cn/neo4j
大家可以在本地安装一个neo4j,然后在自带的浏览器中去执行一些简单的操作命令

总结
这里我们初识了图数据库,知道了图数据库的关系模型,以及了解了neo4j的概念,优缺点,大家有时间可以多去练习neo4j的语法,把它练得和sql一样熟练
下节我们针对通话记录分析这一业务去进行neo4j的使用:
我们通过导入的方式将通话记录的csv文件导入到neo4j中去,并且用springboot的后台去访问这些节点和他们之间的关系,再通过d3去展示出来。
————————————————
上节我们了解了什么是图数据库,作为研究对象的neo4j的特点,优缺点以及基本的环境搭建。
现在我们要讲存储在csv中的通话记录数据导入到neo4j中去,并且可以通过cql去查询导入的数据及关系
1.选取导入方式
neo4j的导入方式有很多,我大概总结了一下:
Cypher CREATE 语句,为每一条数据写一个CREATE
Cypher LOAD CSV 语句,将数据转成CSV格式,通过LOAD CSV读取数据。
官方提供的Java API —— Batch Inserter
大牛编写的 Batch Import 工具
官方提供的 neo4j-import 工具
优缺点对比:
create语句 load csv语句 Batch Inseter Batch Import neo4j-import
适用场景 1~1w nodes 1w~10w nodes 千万以上 nodes 千万以上 nodes 千万以上 nodes
速度 很慢(1000 nodes/s) 一般(5000 nodes/s) 非常快(数万nodes/s) 非常快(数万nodes/s) 非常快(数万nodes/s)
优点 使用方便,可实时插入。 使用方便,可以加载本地 远程CSV;可实时插入 基于Batch Inserter,可以直接运行编译好的jar包;可以在已存在的数据库中导入数据 官方出品,比Batch Import占用更少的资源
缺点 速度慢 需要将数据转换成csv 需要转成CSV;只能在JAVA中使用;且插入时必须停止neo4j 需要转成CSV;必须停止neo4j 需要转成CSV;必须停止neo4j;只能生成新的数据库,而不能在已存在的数据库中插入数据
可以看出导入的方式有很多,由于我们导入的数据量较大,所以我这里选择的是最后一种 neo4j-import,大家也可以去选择其他的导入方式
neo4j-import 使用
我们打开neo4j-import使用的网站可以看到这样的一段摘要
Super Fast Batch Importer For Huge Datasets LOAD CSV is great for
importing small – medium sized data, i.e. up to the 10M records range.
For large data sets, i.e. in the 100B records range, we have access to
a specialized bulk importer.
We want to use it to import similar order data into Neo4j: customers,
orders and contained products.
The tool is located in path/to/neo4j/bin/neo4j-import and is used as
follows:
这段话的大致意思是我们使用load csv无法满足我们大数据量的业务需要,所以我们不得不去选择一种新的导入方式,这里我们选择了neo4j-import这种方式,以下是一个导入的例子
bin/neo4j-import –into retail.db –id-type string \
–nodes:Customer customers.csv –nodes products.csv \
–nodes orders_header.csv,orders1.csv,orders2.csv \
–relationships:CONTAINS order_details.csv \
–relationships:ORDERED customer_orders_header.csv,orders1.csv,orders2.csv
例子中的数据结构为:
如果您调用neo4j-import没有参数的脚本,它将列出一个全面的帮助页面。
该–into retail.db显然是目标数据库,其中不能包含现有数据库。
重复–nodes和–relationships参数是同一实体的多个(可能分裂的)csv文件的组,即具有相同的列结构。
每组的所有文件都被视为可以连接成一个大文件。一个标题行的组的第一个文件是必需的,它甚至可能被包含在其中可能比一个多GB的文本文件更易于处理和编辑一个单行文件。也支持压缩文件。
customers.csv直接作为带有:Customer标签的节点导入,属性直接从文件中获取。
对于从:LABEL列中获取节点标签的产品也是如此。
订单节点取自3个文件,一个标题和两个内容文件。
输入:CONTAINS的order_details.csv订单项关系是通过其ID 来创建的,包含与所包含产品的订单。
订单通过再次使用订单csv文件连接到客户,但这次使用不同的标头,其中:IGNORE是不相关的列
这–id-type string表示所有:ID列都包含字母数字值(对仅数字ID进行优化)。
列名用于节点和关系的属性名称,特定列有一些额外的标记
name:ID – 全局id列,通过该列查找节点以便以后重新连接,
如果保留属性名称,它将不会被存储(临时),这就是–id-type所指的
如果你有跨实体的重复id,你必须在括号中提供实体(id-group) :ID(Order)
如果您的ID是全球唯一的,您可以将其关闭
:LABEL – 节点的标签列,多个标签可以用分隔符分隔
:START_ID,:END_ID- 关系文件列,引用节点ID,用于id-groups使用:END_ID(Order)
:TYPE – 关系型列
所有其他列都被视为属性,但如果为空或在注释时跳过:IGNORE
类型转换可以通过后面添加的名称,例如通过:INT,:BOOLEAN等
导入通话记录数据
在整理后的csv中我们的通话记录是这样的数据:
phones.csv 记录电话号列表,作为nodes结点
phone_header 标题文件只有一行数据
phone:ID
call.csv 该文件记录通话记录的信息,作为以后关系的建立和关系属性的添加
第一行从左到右字段的含义为:
150 **** 0743给136 **** 5301一共打了125分钟时长的电话,打了一次,平均一次125分钟
call_header.csv 通话记录头信息
这里的:START_ID指的是关系的起始点,:END_ID指的是关系的终止点
这些csv文件准备好之后,我们写一段shell脚本来执行这些文件。
import()
{
#导入命令
neo4j stop
cd /usr/local/Cellar/neo4j/3.5.0/libexec/data/databases
rm -rf graph.db
cd /Documents/归档/data
neo4j-admin import \
–database=graph.db
–nodes:phone="../phone_header.csv,phones.csv \
–ignore-duplicate-nodes=true \
–ignore-missing-nodes=true \
–relationships:call="../call_header.csv,call.csv"
neo4j start
}
这里以防我们新建的数据库已经存在,我们选择删除已有库再进行导入
记得要先关闭neo4j
查看结果
导入完成之后我们来打开neo4j浏览器查看一下导入后的结果
我们打开http://localhost:7474/browser/
首先我们先查看一下Database Information
这里我们可以看到已有的结点数,有多少条关系,占用的存储空间等数据库信息
然后我们来查看某个电话号码的交际圈:
match (p:phone{phone:"13825259929"})-[r]->(o) return p,o,r;
1
把鼠标移到对应的结点和关系上时,底部便会出现对应的属性
现在我们的数据导入就完成了
接下来我们要用springboot + neo4j +d3来展示某人的通话记录圈。
————————————————
版权声明:本文为CSDN博主「抓住流浪剑客的小Yi巴」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_32519415/article/details/87942379