最近测试规则,网页上每条测试只能手动点测试,想写个脚本实现自动点击,网上收集资料可以用selenium实现,模拟人操作。
import selenium
from selenium import webdriver
from selenium.webdriver.common.by import By
现收集如下材料:
使用selenium模拟打开谷歌浏览器:
1、要下载浏览器版本对应的ChromeDriver驱动包:下载网址
2、打开谷歌浏览器
# 找打刚才安装的chromedriver.exe的位置
browser = webdriver.Chrome(executable_path =r’D:\chromedriver.exe’)
此时电脑就会新打开谷歌浏览器,并显示受到自动测试软件控制
3、打开某个网址:
browser.get(‘https://www.baidu.com/’)
ps:也可以在此浏览器中自行操作打开网址,找到想要操作的页面,此时停留的页面,就是程序里可以操作的页面。
4、元素定位
参考:史上最全!Selenium元素定位的30种方式
5、常用事件
点击:参考Selenium实现点击click()
6、程序延迟执行
import time
time.sleep(360) # 延迟执行360秒
7、动态更改谷歌浏览器默认下载路径
整理的时候找不到是哪个大神写的了,当时用了他的代码下面贴出来:
def set_download_path(driver, path):
“””
禁止下载弹窗,设置下载路径
“””
# path = path.rstrip(os.sep)
driver.command_executor._commands[“send_command”] = (“POST”, ‘/session/$sessionId/chromium/send_command’)
params = {‘cmd’: ‘Page.setDownloadBehavior’,
‘params’: {‘behavior’: ‘allow’, ‘downloadPath’: path}}
driver.execute(“send_command”, params)
if not os.path.exists(path):
os.makedirs(path)
——————————————————–分割——————————————————————————————
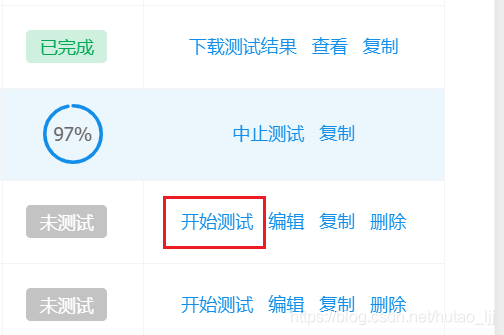
第一需求是在这样一个页面中,等待上一条测试完成后,自动点击下一条‘开始测试’(测试完成的及进行中的就不会在出现‘开始测试’字样)
初级实现功能代码:
由于短时间没找打怎么监控进度到100%的方法,通过一个简单方法:每条测试大概需要5分钟左右,就设定每隔6分钟点击一次,也基本满足需求。
import selenium
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
# 打开谷歌浏览器,
browser = webdriver.Chrome(executable_path =r’D:\chromedriver.exe’)
# 手动找到需要操作的页面
for j in range(5): # 需要点击5页
f= browser.find_elements_by_link_text(‘开始测试’) # 找到当前页所有的开始测试元素
for i in range(len(f)): # 循环每隔6分钟点击一个
f[i].click()
time.sleep(360)
browser.find_elements_by_class_name(‘ant-pagination-item-link’)[2].click() # 这一页的开始测试都点完后,点击下一页
time.sleep(4)
改进版,发现有进度的时候会有class:ant-progress-text,text会显示进度百分之多少,测试成功后就会变成其他,所以通过判断当时是否有ant-progress-text来判断当前是否测试完毕,并可以开始下一条测试。
for j in range(5):
f= browser.find_elements_by_link_text(‘开始测试’)
for i in range(len(f)):
f[i].click()
time.sleep(5)
while True:
try:
browser.find_element_by_class_name(‘ant-progress-text’).text # 如果没有ant-progress-text,会报错
time.sleep(30)
except :
break
browser.find_elements_by_class_name(‘ant-pagination-item-link’)[3].click()
time.sleep(4)
第二个需求是对于测试完毕的需要下载测试结果,点击‘下载测试结果’会下载一个csv文件,下面实现自动下载,且每个文件保存在新文件中,文件夹以测试名称命名。
r = browser.find_elements_by_link_text(‘下载测试结果’) # 找下载测试结果
a = browser.find_elements_by_xpath(“//tbody//tr”) # 找每条测试的名称
for i in range(9):
file_name = a[i].text.split(‘ ‘)[2]
path = r’C:\Users\99452\Desktop\下载结果\{}’.format(file_name)
set_download_path(browser,path) # 用到上述第7点更改默认文件夹的函数
time.sleep(10)
r[i].click()
time.sleep(20)
————————————————
版权声明:本文为CSDN博主「胡桃夹子zy」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/hutao_ljj/article/details/112059679