
1.为什么要学Excel
存测试数据
有时候有大批量的数据,存到TXT文件里面显然不是最佳的方式,我们可以存到Excel里面去,第一方便我们存数据和做数据,另一方面方便我们读取数据,比较明朗。测试的时候就从数据库中读取出来,这点是非常重要的。
存测试结果
可以批量把结果存入到Excel中,也是比较好整理数据点,比我们的TXT要好。
2.安装openpyxl
python中与excel操作相关的模块:
- xlrd库:从excel中读取数据,支持xls、xlsx
- xlwt库:对excel进行修改操作,不支持对xlsx格式的修改
- xlutils库:在xlw和xlrd中,对一个已存在的文件进行修改。
- openpyxl:主要针对xlsx格式的excel进行读取和编辑。
安装方式:pip install openpyxl
3.Excel中的三大对象
- WorkBook:工作簿对象
- Sheet:表单对象
- 创建一个工作薄:wb = openpyxl.Workbook()
- 新增一个sheet表单:wb.create_sheet(‘test_case’)
- 保存case.xlsx文件:wb.save(‘cases.xlsx’)
- 打开工作簿:wb = openpyxl.load_workbook(‘cases.xlsx’)
- 选取表单:sh = wb[‘Sheet1’
- 读取第一行、第一列的数据:ce = sh.cell(row = 1,column = 1)
- 按行读取数据:row_data = list(sh.rows)
- 关闭工作薄:wb.close()
- 按列读取数据:columns_data = list(sh.columns)
- 写入数据之前,该文件一定要处于关闭状态
- 写入第一行、第四列的数据 value = ‘result’:sh.cell(row = 1,column = 4,value = ‘result’)
- 获取最大行总数、最大列总数:sh.max_row、sh.max_column
- del 删除表单的用法:del wb[‘sheet_name’]
- remove 删除表单的用法:sh = wb[‘sheet_name’] wb.remove(sh)

1 import openpyxl
2 # 创建一个工作簿
3 wb = openpyxl.Workbook()
4 # 创建一个test_case的sheet表单
5 wb.create_sheet('test_case')
6 # 保存为一个xlsx格式的文件
7 wb.save('cases.xlsx')
8 # 读取excel中的数据
9 # 第一步:打开工作簿
10 wb = openpyxl.load_workbook('cases.xlsx')
11 # 第二步:选取表单
12 sh = wb['Sheet1']
13 # 第三步:读取数据
14 # 参数 row:行 column:列
15 ce = sh.cell(row = 1,column = 1) # 读取第一行,第一列的数据
16 print(ce.value)
17 # 按行读取数据 list(sh.rows)
18 print(list(sh.rows)[1:]) # 按行读取数据,去掉第一行的表头信息数据
19 for cases in list(sh.rows)[1:]:
20 case_id = cases[0].value
21 case_excepted = cases[1].value
22 case_data = cases[2].value
23 print(case_excepted,case_data)
24 # 关闭工作薄
25 wb.close()
三.封装一个读取用例的excel类:用来实现读取数据和写入数据的功能
cases.xlsx的测试数据:
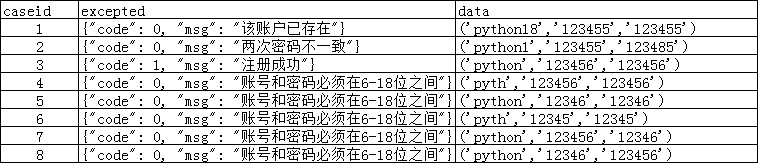
1.按行读取数据,存储在列表中
1 import openpyxl
2 class Case: #这个类用来存储用例的
3 __slots__ = [] #特殊的类属性,可以用来限制这个类创建的实例属性添加 可写可不写
4 pass
5
6 class ReadExcel(object): #读取excel数据的类
7 def __init__(self,file_name,sheet_name):
8 """
9 这个是用来初始化读取对象的
10 :param file_name: 文件名 ---> str类型
11 :param sheet_name: 表单名 ———> str类型
12 """
13 # 打开文件
14 self.wb = openpyxl.load_workbook(file_name)
15 # 选择表单
16 self.sh = self.wb[sheet_name]
17 def read_data_line(self):
18 #按行读取数据转化为列表
19 rows_data = list(self.sh.rows)
20 # print(rows_data)
21 # 获取表单的表头信息
22 titles = []
23 for title in rows_data[0]:
24 titles.append(title.value)
25 # print(titles)
26 #定义一个空列表用来存储测试用例
27 cases = []
28 for case in rows_data[1:]:
29 # print(case)
30 data = []
31 for cell in case: #获取一条测试用例数据
32 # print(cell.value)
33 data.append(cell.value)
34 # print(data)
35 #判断该单元格是否为字符串,如果是字符串类型则需要使用eval();如果不是字符串类型则不需要使用eval()
36 if isinstance(cell.value,str):
37 data.append(eval(cell.value))
38 else:
39 data.append(cell.value)
40 #将该条数据存放至cases中
41 # print(dict(list(zip(titles,data))))
42 case_data = dict(list(zip(titles,data)))
43 cases.append(case_data)
44 return cases
45 if __name__ == '__main__':
46 r = ReadExcel('cases.xlsx','Sheet1')
47 data1 = r.read_data_line()
48 print(data1)
2.按行读取数据,存储在对象中
1 import openpyxl
2 class Case:
3 pass
4 class ReadExcel(object):
5 def __init__(self,filename,sheetname):
6 self.wb = openpyxl.load_workbook(filename)
7 self.sh = self.wb[sheetname]
8 def read_data_obj(self):
9 """
10 按行读取数据 每条用例存储在一个对象中
11 :return:
12 """
13 rows_data = list(self.sh.rows)
14 # print(rows_data)
15 # 获取表单的表头信息
16 titles = []
17 for title in rows_data[0]:
18 titles.append(title.value)
19 # print(titles)
20 # 定义一个空列表用来存储测试用例
21 cases = []
22 for case in rows_data[1:]:
23 # print(case)
24 #创建一个Case类的对象,用来保存用例数据
25 case_obj = Case()
26 data = []
27 for cell in case: # 获取一条测试用例数据
28 # print(cell.value)
29 # data.append(cell.value)
30 # print(data)
31 if isinstance(cell.value,str): # 判断该单元格是否为字符串,如果是字符串类型则需要使用eval();如果不是字符串类型则不需要使用eval()
32 data.append(eval(cell.value))
33 else:
34 data.append(cell.value)
35 # 将该条数据存放至cases中
36 # print(dict(list(zip(titles,data))))
37 case_data = list(zip(titles, data))
38 # print(case_data)
39 for i in case_data:
40 setattr(case_obj,i[0],i[1])
41 # print(case_obj)
42 # print(case_obj.case_id,case_obj.data,case_obj.excepted)
43 cases.append(case_obj)
44 return cases
45 if __name__ == '__main__':
46 r = ReadExcel('cases.xlsx','Sheet1')
47 res = r.read_data_obj()
48 for i in res:
49 print(i.caseid, i.excepted, i.data)
3.将测试用例封装到列表中,读取指定列的数据
1 import openpyxl
2 class Case:
3 pass
4 class ReadExcelZy(object):
5 def __init__(self,filename,sheetname):
6 self.wb = openpyxl.load_workbook(filename)
7 self.sheet = self.wb[sheetname]
8 # list1 参数为一个列表,传入的是指定读取数据的列,比如[1,2,3]
9 # 每一行[1,3,5]列的数据,读取出来就作为一条测试用例,放在字典中
10 # 所有的用例放在列表中并且进行返回
11 def read_data(self,list1):
12 """
13 :param list1: list--->要读取列 list类型
14 :return: 返回一个列表,每一个元素为一个用例(用例为dict类型)
15 """
16 # 获取最大的行数
17 max_r = self.sheet.max_row
18 cases = [] #定义一个空列表,用来存放所有的用例数据
19 titles = [] #定义一个空列表,用来存放表头
20 # 遍历所有的行数据
21 for row in range(1,max_r+1):
22 if row != 1: #判断是否是第一行
23 case_data = [] #定义一个空列表,用来存放该行的用例数据
24 for column in list1:
25 info = self.sheet.cell(row,column).value
26 # print(info)
27 case_data.append(info)
28 # print(list(zip(titles,case_data)))
29 case = dict(zip(titles,case_data)) #将该条数据和表头进行打包组合,作用相当于dict(list(zip(titles,case_data)))
30 # print(case)
31 cases.append(case)
32 # print(cases)
33 else: #获取表头数据
34 for column in list1:
35 title = self.sheet.cell(row,column).value
36 titles.append(title)
37 # print(titles)
38 return cases
39 if __name__ == '__main__':
40 r = ReadExcelZy("cases.xlsx","Sheet1")
41 res = r.read_data([1,2,3])
42 for o in res:
43 print(o['caseid'],o['data'],o['excepted'])
4.将测试用例封装到对象中,读取指定列的数据
1 import openpyxl
2 class Case:
3 pass
4 class ReadExcelZy(object):
5 def __init__(self,filename,sheetname):
6 self.wb = openpyxl.load_workbook(filename)
7 self.sheet = self.wb[sheetname]
8
9 # list1 参数为一个列表,传入的是指定读取数据的列,比如[1,2,3]
10 # 每一行[1,3,5]列的数据,读取出来就作为一条测试用例,放在字典中
11 # 所有的用例放在对象中并且进行返回
12 def read_data_obj(self,list2):
13 max_r1 = self.sheet.max_row #获取最大行数
14 cases = []
15 titles = [] #用来存放表头数据
16 for row in range(1,max_r1+1):
17 if row != 1:
18 case_data = []
19 for column in list2:
20 info = self.sheet.cell(row,column).value
21 # print(info)
22 case_data.append(info)
23 cases_data = list(zip(titles,case_data))
24 #将一条用例存到一个对象中(每一列对应对象的一个属性)
25 case_obj = Case()
26 for i in cases_data:
27 # print(i)
28 setattr(case_obj,i[0],i[1])
29 # print(case_obj.caseid,case_obj.excepted,case_obj.data)
30 cases.append(case_obj)
31 else:
32 for column in list2:
33 title = self.sheet.cell(row,column).value
34 titles.append(title)
35 return cases
36 if __name__ == '__main__':
37 r = ReadExcelZy("cases.xlsx","Sheet1")
38 res = r.read_data_obj([1,2,3])
39 for i in res:
40 print(i.caseid,i.data,i.excepted)
5.优化第4部分代码,将设置对象属性写在初始化方法中(封装Excel类读取数据最常用的方法)
1 import openpyxl
2 class Case: # 这个类用来存储用例的
3 def __init__(self, attrs):
4 """
5 初始化用例
6 :param attrs:zip类型——>[{key,value},(key1,value1)......]
7 """
8 for i in attrs:
9 setattr(self, i[0], i[1])
10 class ReadExcel(object):
11 def __init__(self, filename, sheetname):
12 """
13 定义需要打开的文件及表名
14 :param filename: 文件名
15 :param sheetname: 表名
16 """
17 self.wb = openpyxl.load_workbook(filename)
18 self.sheet = self.wb[sheetname]
19 def read_data_obj_new(self, list2):
20 # 获取最大行数
21 max_r1 = self.sheet.max_row
22 cases = []
23 # 用来存放表头数据
24 titles = []
25 for row in range(1, max_r1 + 1):
26 if row != 1:
27 case_data = []
28 for column in list2:
29 info = self.sheet.cell(row, column).value
30 # print(info)
31 case_data.append(info)
32 case = list(zip(titles, case_data))
33 # 新建对象时,将对象传给Case类
34 case_obj = Case(case)
35 # print(case_obj.caseid,case_obj.excepted,case_obj.data)
36 cases.append(case_obj)
37 else:
38 # 获取表头
39 for column in list2:
40 title = self.sheet.cell(row, column).value
41 titles.append(title)
42 if None in titles:
43 raise ValueError("传入的表头的数据有显示为空")
44 return cases
45 if __name__ == '__main__':
46 r = ReadExcel('cases.xlsx', 'Sheet1')
47 res1 = r.read_data_obj_new([1, 2, 3])
48 for i in res1:
49 print(i.caseid, i.data, i.excepted)
三.完整流程的代码
一、将测试数据参数化
1 import unittest
2 from python.register_new.register import register
3 from python.register_new.register_testcase_new import RegisterTestCase
4 from HTMLTestRunnerNew import HTMLTestRunner
5 class RegisterTestCase(unittest.TestCase):
6 # 初始化测试用例
7 def __init__(self,modethod_name,excepted,data):
8 # modethod_name 测试用例方法名
9 super().__init__(modethod_name)
10 # excepted 测试用例的预期结果
11 self.excepted = excepted
12 # data 测试用例参数值
13 self.data = data
14
15 def setUp(self):
16 print("准备测试环境,执行测试用例之前会执行此操作")
17
18 def tearDown(self):
19 print("还原测试环境,执行完测试用例之后会执行此操作")
20
21 def test_register(self):
22 res = register(*self.data)
23 try:
24 self.assertEquals(self.excepted,res)
25 except AssertionError as e:
26 print("该条测试用例执行未通通过")
27 raise e
28 else:
29 print("该条测试用例执行通过")
30
31 # 创建测试套件
32 suite = unittest.TestSuite()
33
34 # 将测试用例添加至测试套件中
35 case = [{'excepted':'{"code": 1, "msg": "注册成功"}','data':'('python1', '123456','123456')'},
36 {'excepted':'{"code": 0, "msg": "两次密码不一致"}','data':'('python1', '1234567','123456')'}]
37 for case in cases:
38 suite.addTest(RegisterTestCase('test_register',case['excepted'],case['data']))
39
40 # 执行测试套件,生成测试报告
41 with open("report.html",'wb') as f:
42 runner = HTMLTestRunner(
43 stream = f,
44 verbosity = 2,
45 title = 'python_test_report',
46 description = '这是一份测试报告',
47 tester = 'WL'
48 )
49 runner.run(suite)
二.将调用封装好的Excel类的完整代码流程
import unittest
from python.register_new.register import register
from python.register_new.register_testcase_new import RegisterTestCase
from HTMLTestRunnerNew import HTMLTestRunner
from python.readexcel import ReadExcel
class RegisterTestCase(unittest.TestCase):
# 初始化测试用例
def __init__(self, modethod_name, excepted, data):
# modethod_name 测试用例方法名
super().__init__(modethod_name)
# excepted 测试用例的预期结果
self.excepted = excepted
# data 测试用例参数值
self.data = data
def setUp(self):
print("准备测试环境,执行测试用例之前会执行此操作")
def tearDown(self):
print("还原测试环境,执行完测试用例之后会执行此操作")
def test_register(self):
res = register(*self.data)
try:
self.assertEquals(self.excepted, res)
except AssertionError as e:
print("该条测试用例执行未通通过")
raise e
else:
print("该条测试用例执行通过")
# 创建测试套件
suite = unittest.TestSuite()
# 调用封装好的读取数据的Excel类,获取测试数据
r1 = ReadExcel('cases.xlsx', 'Sheet1')
cases = r1.read_data_obj_new([2, 3])
# 将测试用例添加至测试套件中
for case in cases:
# 需要使用eval()函数对except和data进行自动识别
suite.addTest(RegisterTestCase('test_register', eval(case.excepted), eval(case.data)))
# 执行测试套件,生成测试报告
with open("report.html", 'wb') as f:
runner = HTMLTestRunner(
stream=f,
verbosity=2,
title='python_test_report',
description='这是一份测试报告',
tester='WL')
runner.run(suite)
转自:https://www.cnblogs.com/wanglle/p/11455758.html