opencv+python+pycharm实现人脸识别
目录
前言
前期准备
人脸检测
样本采集
样本训练
结语
前言
本人本科在校大二学生,编程小菜鸟。近期做了期末课程设计,我选择的题目就是人脸识别。第一次写博客,想把做系统的整个过程记录下来,方便后续使用。我是站在巨人的肩膀上做成人脸识别的,下面是我参考的博客。
https://www.cnblogs.com/xp12345/p/9818435.html(最终参考)
https://blog.csdn.net/WALRE_HUNTER_RICO/article/details/88361212
前期准备
Pycharm(需要安装一些第三方包)
Opencv340(版本最好不要太高,版本会影响程序运行)
人脸检测
上代码来(未知大神的)
import numpy as np
import cv2
# 人脸识别分类器
faceCascade = cv2.CascadeClassifier(r’F:/face_test01/haarcascade_frontalface_default.xml’)
# 识别眼睛的分类器
eyeCascade = cv2.CascadeClassifier(r’F:/face_test01/haarcascade_eye.xml’)
# 开启摄像头
cap = cv2.VideoCapture(0)
ok = True
result = []
while ok:
# 读取摄像头中的图像,ok为是否读取成功的判断参数
ok, img = cap.read()
# 转换成灰度图像
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 人脸检测
faces = faceCascade.detectMultiScale(
gray,
scaleFactor=1.2,
minNeighbors=5,
minSize=(32, 32)
)
# 在检测人脸的基础上检测眼睛
for (x, y, w, h) in faces:
fac_gray = gray[y: (y+h), x: (x+w)]
result = []
eyes = eyeCascade.detectMultiScale(fac_gray, 1.3, 2)
# 眼睛坐标的换算,将相对位置换成绝对位置
for (ex, ey, ew, eh) in eyes:
result.append((x+ex, y+ey, ew, eh))
# 画矩形
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x+w, y+h), (255, 0, 0), 2)
for (ex, ey, ew, eh) in result:
cv2.rectangle(img, (ex, ey), (ex+ew, ey+eh), (0, 255, 0), 2)
cv2.imshow(‘video’, img)
k = cv2.waitKey(1)
if k == 27: # press ‘ESC’ to quit
break
cap.release()
cv2.destroyAllWindows()
注:注意上面两个分类器的路径要改成自己文件所在路径
样本采集
上代码!(大神的)
import cv2
import os
# 调用笔记本内置摄像头,所以参数为0,如果有其他的摄像头可以调整参数为1,2
cap = cv2.VideoCapture(0)
# CascadeClassifier,是Opencv中做人脸检测的时候的一个级联分类器
face_detector = cv2.CascadeClassifier(‘haarcascade_frontalface_default.xml’)
face_id = input(‘\n enter user id:’)
print(‘\n Initializing face capture. Look at the camera and wait …’)
count = 0
while True:
# 从摄像头读取图片
sucess, img = cap.read()
# 转为灰度图片
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 检测人脸
faces = face_detector.detectMultiScale(gray, 1.3, 5)
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x+w, y+w), (255, 0, 0))
count += 1
# 保存图像
cv2.imwrite(“Facedata/User.” + str(face_id) + ‘.’ + str(count) + ‘.jpg’, gray[y: y + h, x: x + w])
cv2.imshow(‘image’, img)
# 保持画面的持续。
k = cv2.waitKey(1)
if k == 27: # 通过esc键退出摄像
break
elif count >= 1000: # 得到1000个样本后退出摄像
break
# 关闭摄像头
cap.release()
cv2.destroyAllWindows()
注:1.在运行该程序前,请先创建一个Facedata文件夹并和你的程序放在一个文件夹下。
(友情提示:请将程序和文件打包放在一个叫人脸识别的文件夹下。可以把分类器也放入其中。)
2.程序运行过程中,会提示你输入id,请从0开始输入,即第一个人的脸的数据id为0,第二个人的脸的数据id为1,运行一次可收集一张人脸的数据。(这个很重要,将会影响到后面人脸识别中人名列表)
3.程序运行时间可能会比较长,可能会有几分钟,如果嫌长,可以将1000改为100。
4.关于训练样本,我训练了15000张,三个人。有一个问题还没弄明白:样本数量变多(例如训练两万)是,在后面人脸识别时会报错。
如果实在等不及,可按esc退出,但可能会导致数据不够模型精度下降。
训练样本
上代码(大神的)
import numpy as np
from PIL import Image
import os
import cv2
# 人脸数据路径
path = “F:/face_test01/Facedata”
# 使用OpenCV中LBPH算法的方法建立人脸数据模型
recognizer = cv2.face.LBPHFaceRecognizer_create()
detector = cv2.CascadeClassifier(“haarcascade_frontalface_default.xml”)
def getImagesAndLabels(path):
imagePaths = [os.path.join(path, f) for f in os.listdir(path)] # join函数的作用?
faceSamples = []
ids = []
for imagePath in imagePaths:
PIL_img = Image.open(imagePath).convert(‘L’) # convert it to grayscale
img_numpy = np.array(PIL_img, ‘uint8’) # 图片格式转换
id = int(os.path.split(imagePath)[-1].split(“.”)[1])
faces = detector.detectMultiScale(img_numpy) # 人脸检测
for (x, y, w, h) in faces:
faceSamples.append(img_numpy[y:y + h, x: x + w])
ids.append(id)
return faceSamples, ids
print(‘Training faces. It will take a few seconds. Wait …’)
faces, ids = getImagesAndLabels(path)
recognizer.train(faces, np.array(ids))
recognizer.write(r’face_trainer\trainer.yml’)
print(“{0} faces trained. Exiting Program”.format(len(np.unique(ids))))
注:运行该程序前,请在人脸识别文件夹下创建face_trainer文件夹,并修改文件路径。(1处)
人脸检测
代码(大神的)
import cv2
recognizer = cv2.face.LBPHFaceRecognizer_create()
recognizer.read(‘face_trainer/trainer.yml’)
cascadePath = “haarcascade_frontalface_default.xml”
faceCascade = cv2.CascadeClassifier(cascadePath)
font = cv2.FONT_HERSHEY_SIMPLEX
idnum = 0
names = [‘Allen’, ‘Bob’]
cam = cv2.VideoCapture(0)
minW = 0.1*cam.get(3)
minH = 0.1*cam.get(4)
while True:
ret, img = cam.read()
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = faceCascade.detectMultiScale(
gray,
scaleFactor=1.2,
minNeighbors=5,
minSize=(int(minW), int(minH))
)
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 2)
idnum, confidence = recognizer.predict(gray[y:y+h, x:x+w])
if confidence < 100:
idnum = names[idnum]
confidence = “{0}%”.format(round(100 – confidence))
else:
idnum = “unknown”
confidence = “{0}%”.format(round(100 – confidence))
cv2.putText(img, str(idnum), (x+5, y-5), font, 1, (0, 0, 255), 1)
cv2.putText(img, str(confidence), (x+5, y+h-5), font, 1, (0, 0, 0), 1)
cv2.imshow(‘camera’, img)
k = cv2.waitKey(10)
if k == 27:
break
cam.release()
cv2.destroyAllWindows()
注:names列表中存储人的名字,若该人id为0则他的名字在第一位,id位1则排在第二位,以此类推。另外,这儿很容易出现这个错误:
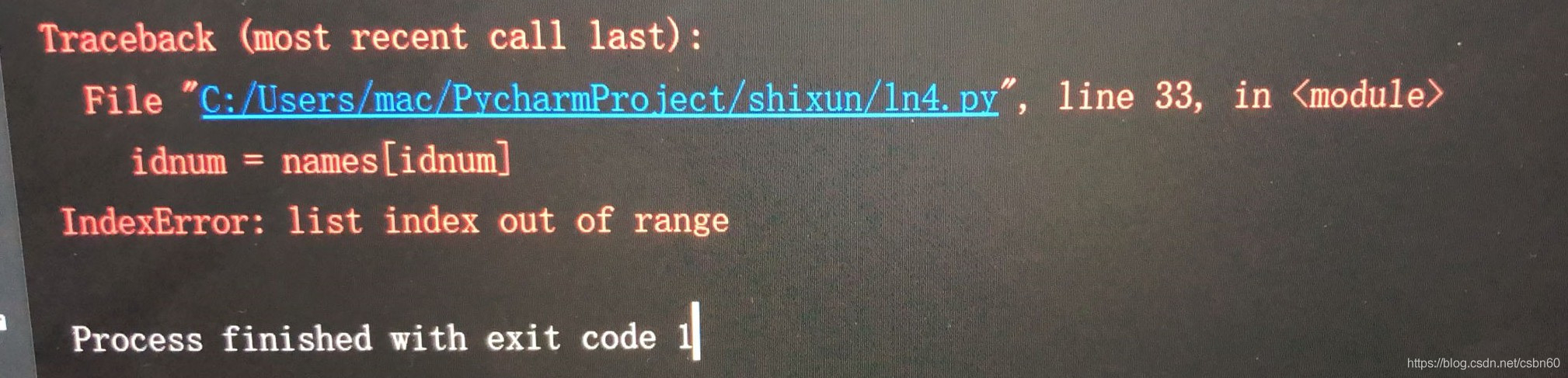
这个问题我想有两个原因:
1.在前面采集样本输入ID时,输了字母,而不是索引数字(0,1,…)。
2.训练人数与列表中数量不对应。
结语
总体来说,由于站在巨人的肩膀上,用了网上的开源代码,并且基本不需要改动,所以做出整个人脸识别系统还是比较容易和快速的。我所做的工作就是针对出现的小问题,例如文件路径等做些调试。最后真的很感谢网上程序员们,他们无私的分享给我们这些小白撑起了一片天。
————————————————
版权声明:本文为CSDN博主「csbn60」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/csbn60/article/details/106858652/