
1. Hadoop 概览
Google 三篇论文(GFS -> HDFS,Map-Reduce -> MR,BigTable -> HBase)是 Hadoop 的思想之源。Hadoop 生态非常庞大,其最初两大核心是 HDFS 和 MR,分别负责存储和计算(Hadoop 1.x 中,MR 既负责计算又负责资源调度,Hadoop 2.x,搞出 Yarn 负责调度,MR 只负责计算),由于 MR 被 Spark 取代,下面只简要看下 HFDS 和 Yarn。
Hadoop 环境搭建参考博文,个人学习毕竟受限个人笔记本资源限制,故而使用伪分布式方式。启动后可以访问 http://localhost:50070/ 查看 HDFS 情况。
HDFS 架构概述
图片来自官方文档
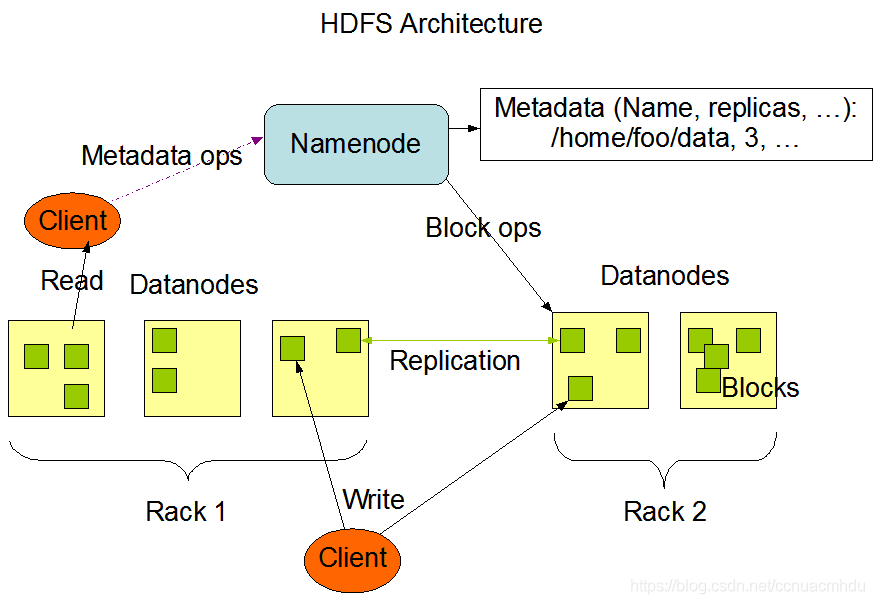
NameNode,存储文件的元数据,如文件名、目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的 DataNode 等。
DataNode,在本地文件系统存储文件块数据,以及块数据的校验和。
Secondary NameNode,用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
HDFS 常见命令
注意结合 HDFS 的 UI 界面 http://localhost:50070/ 查看此文件系统的目录和文件(Utilities)等状态!
// 查看命令使用帮助
hadoop fs -help rm
// 查看根目录下文件(等价为 hadoop fs -ls hdfs://localhost:9000/,如果去掉最后边的 / ,将是查看最内层所有文件)
hadoop fs -ls /
// 递归创建目录(注意 / 开头)
hadoop fs -mkdir -p /test/test/test
// 递归删除目录(注意 / 开头)
hadoop fs -rm -r /test
更多命令见官网,用时结合百度查看使用即可。
HDFS 开发
在 Maven 中引入 HDFS 相关依赖包即可
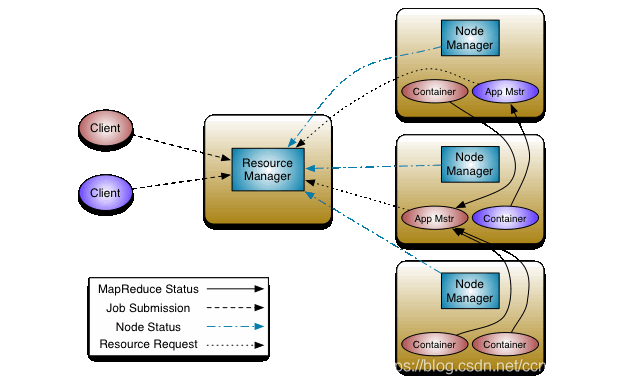
Yarn 架构概述
2. 安装 VirtualBox
官网下载最新版本 VirtualBox 并安装,此过程简单,可结合百度。笔者使用 VirtualBox-6.1.10-138449-Win.exe。
3. 安装 Ubuntu
官网下载最新版本 Ubuntu 并安装到 VirtualBox 中,此过程简单,可结合百度。笔者使用 ubuntu-20.04-desktop-amd64.iso。最好开辟的硬盘空间大点,最起码 20G 吧,不然后续如果不够用,再扩容就比较麻烦了!!笔者在当前用户目录下建立了一个 env 文件夹,专门安装后面的各个环境。
4. 安装 Hadoop
3.1 安装 JDK
官网下载并解压到 env 文件夹,tar -xzf jdk-8u251-linux-x64.tar.gz,可利用mv jdk-8u251-linux-x64.tar.gz jdk重命名为 jdk。配置环境变量,在sudo vi ~/.bashrc最后加入下面的几行配置,并source ~/.bashrc生效,最后用javac和java试试是否安装成功。
export JAVA_HOME=jdk安装路径
export JRE_HOME=$JAVA_HOME/jre
export PATH=${JAVA_HOME}/bin:$PATH
3.2 安装 Hadoop
官网下载并解压到 env 文件夹并重命名为 hadoop,笔者使用的是 hadoop-2.6.4.tar.gz 。如下配置环境变量并使之生效(类似于 JDK 环境变量配置)。并使用hadoop version试试是否安装成功。
export HADOOP_HOME=Hadoop安装路径
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
伪分布式配置 Hadoop
修改core-site.xml,将修改为:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:Hadoop解压路径/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
修改hdfs-site.xml,将修改为:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:Hadoop解压路径/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:Hadoop解压路径/tmp/dfs/data</value>
</property>
</configuration>
把 hadoop-env.sh 中的 ${JAVA_HOME} 改为 JDK 实际路径。
在 Hadoop 的 bin 目录下,使用命令hdfs namenode -format格式化 Namenode,注意观察有“Exiting with status 0”提示表示成功。
在 Hadoop 的 sbin 目录下,使用命令./start-dfs.sh来开启 Namenode 和 Datanode,使用命令./start-yarn.sh启动 Yarn,然后使用jps试试是否启动成功。
52624 Jps
16405 NameNode
16742 SecondaryNameNode
52598 NodeManager
16526 DataNode
52431 ResourceManager
5. 安装 Hive
4.1 安装 Hive
官方下载并解压到 env 文件夹里,并重命名为 hive,配置环境变量并使之生效。笔者使用 apache-hive-2.3.7-bin.tar.gz。
export HIVE_HOME=Hive安装路径
export HIVE_CONF=$HIVE_HOME/conf
export PATH=$PATH:$HIVE_HOME/bin
配置hive-site.xml
复制一份 hive-default.xml.template 并更改名字为 hive-site.xml,cp hive-default.xml.template hive-site.xml。然后如下修改对应的 value 的值。并把${system:java.io.tmpdir}全部替换为hive解压路径/tmp,将{system:user.name}全部替换为${user.name}。
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?characterEncoding=UTF-8&createDatabaseIfNotExist=true</value>
<description>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
4.2 安装 MySQL
1. 安装 MySQL
官网下载 MySQL,并解压到 env 文件夹下的 mysql 文件夹下,笔者使用 mysql-server_5.7.30-1ubuntu18.04_amd64.deb-bundle.tar。
下面是具体安装步骤,如果出现安装失败或者曾经安装过 MySQL,彻底卸载 MySQL 的方法可参考这篇博文。
#安装步骤
sudo apt-get install libaio1
#使用以下命令预配置MySQL服务器软件包(将被要求为root用户提供您的MySQL安装密码):
sudo dpkg-preconfigure mysql-community-server_*.deb
#对于MySQL服务器的基本安装,请按照数据库公用文件包,客户端包,客户端元包,服务器包和服务器元包的顺序如下逐一安装:
sudo dpkg -i mysql-common_*.deb
sudo dpkg -i mysql-community-client_*.deb
sudo dpkg -i mysql-client_*.deb
sudo dpkg -i mysql-community-server_*.deb
sudo dpkg -i mysql-server_*.deb
#如果中途被dpkg警告未满足的依赖关系,可用apt-get来修复它们,然后再运行中断的命令:
sudo apt-get -f install
service mysql start启动 MySQL 可登录试试是否安装成功!
2. 配置 MySQL 的 Java 驱动包
官方下载 MySQL 的 Java 驱动包,笔者使用 mysql-connector-java-5.1.49.tar.gz。把解压出来的 mysql-connector-java-5.1.49-bin.jar 放入 hive 的 lib 目录中。
3. 创建 Hive 的用户及数据库
在 MySQL 数据库中创建用户名和密码均为 hive 的用户,并赋予其所有数据库的权限。然后使用 hive 账号登录,并创建名字为 hive 的数据库。
mysql -u root -p
create user ‘hive’@’%’ identified by ‘hive’;
grant all privileges on *.* to ‘hive’@’localhost’ identified by ‘hive’;
4. 启动 Hive
在 hive 的 bin 目录下,执行schematool -dbType mysql -initSchema完成元数据的初始化,然后命令行通过hive命令(要保证前面已经在 Hadoop 的 sbin 目录下执行了./start-dfs.sh和./start-yarn.sh,并启动了 MySQL)就可使用 Hive 啦!至此,恭喜一路安装成功了!
6. Hive 入门
Hive 是基于 Hadoop 的数据仓库工具,可将结构化数据映射成 Hive 表,并提供类似 SQL 的查询(底层还是转换成 MR 任务)。
通常用 MySQL 的 hive 数据库的各个表存放 Hive 数据的元数据信息。
内部表/外部表
Hive 创建的内部表和外部表,外部表删除后,HDFS 里不会删除。
hive> create external table person2(
> id int,
> name string,
> age int
> )
> ;
建表
# 查询建表,person3 和 person2 的结构、数据完全一致
create table person3
as
select * from person2;
# person4 和 person2 的结构一致,但无数据
create table person4 like person2;
# 加载数据到表,要满足 person4 和 person2 的结构是一致的
insert into person4
select * from person2
# 从文件加载数据到表
create table if not exists person5(
id int comment ‘ID’,
name string comment ‘name’
)
comment ‘created by Mr Hah’
row format delimited
fields terminated by ‘,’
lines terminated by ‘\n’;
load data local inpath ‘/home/data/person5.txt’ into table person5;

特殊数据类型 array/map/struct
array
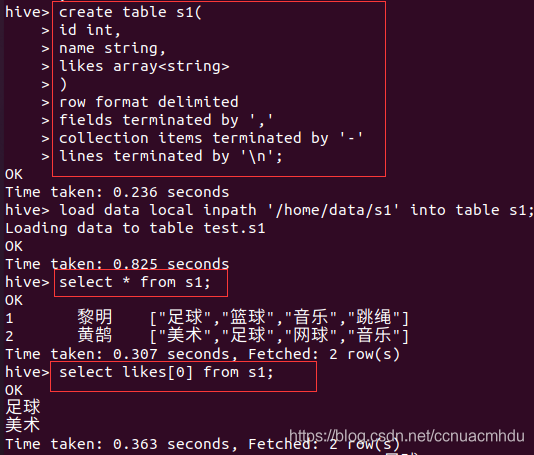
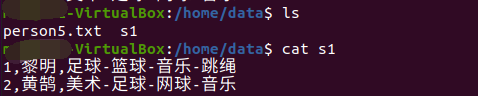
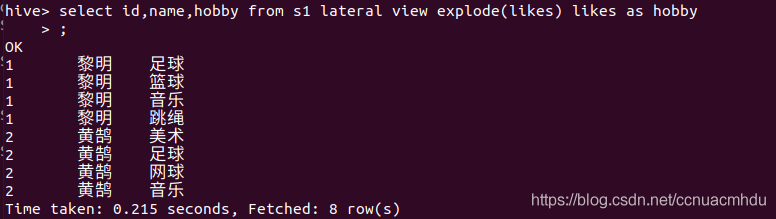
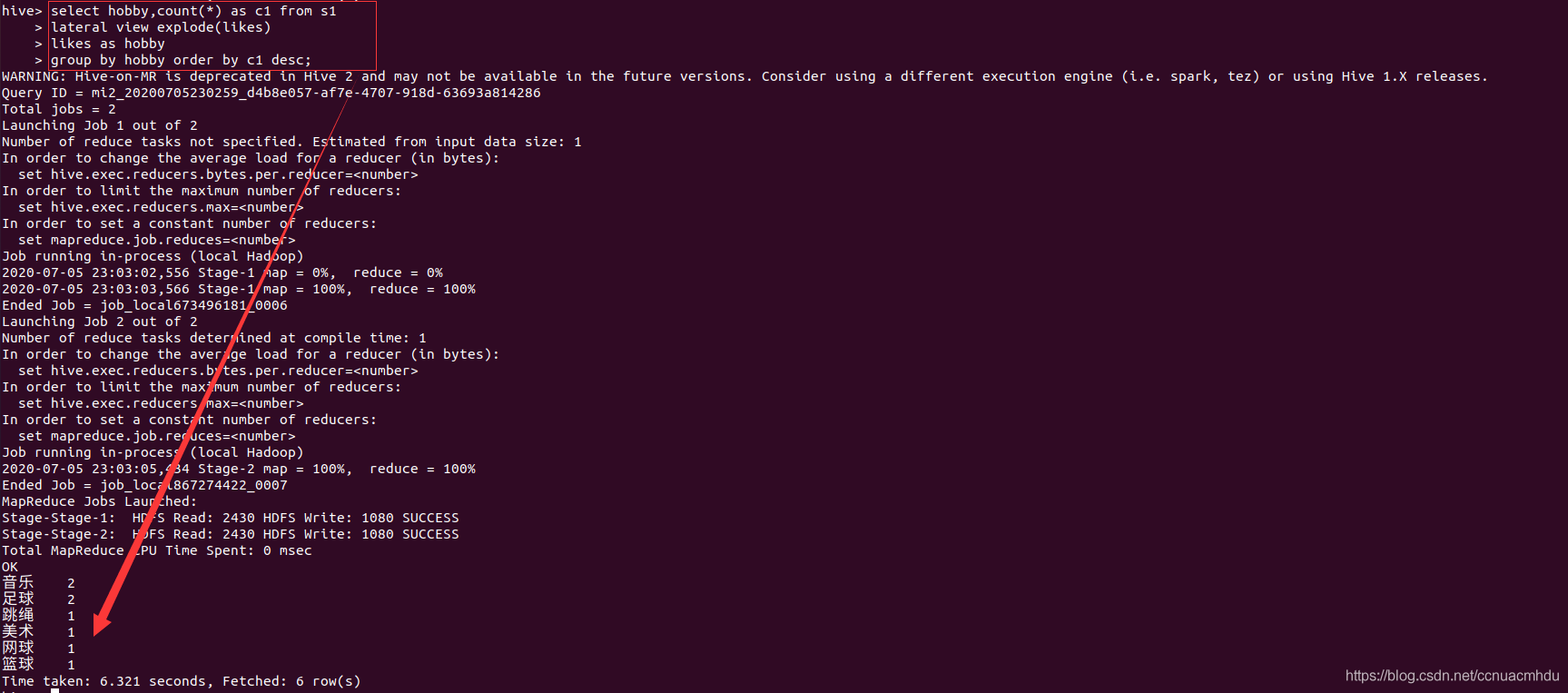
map

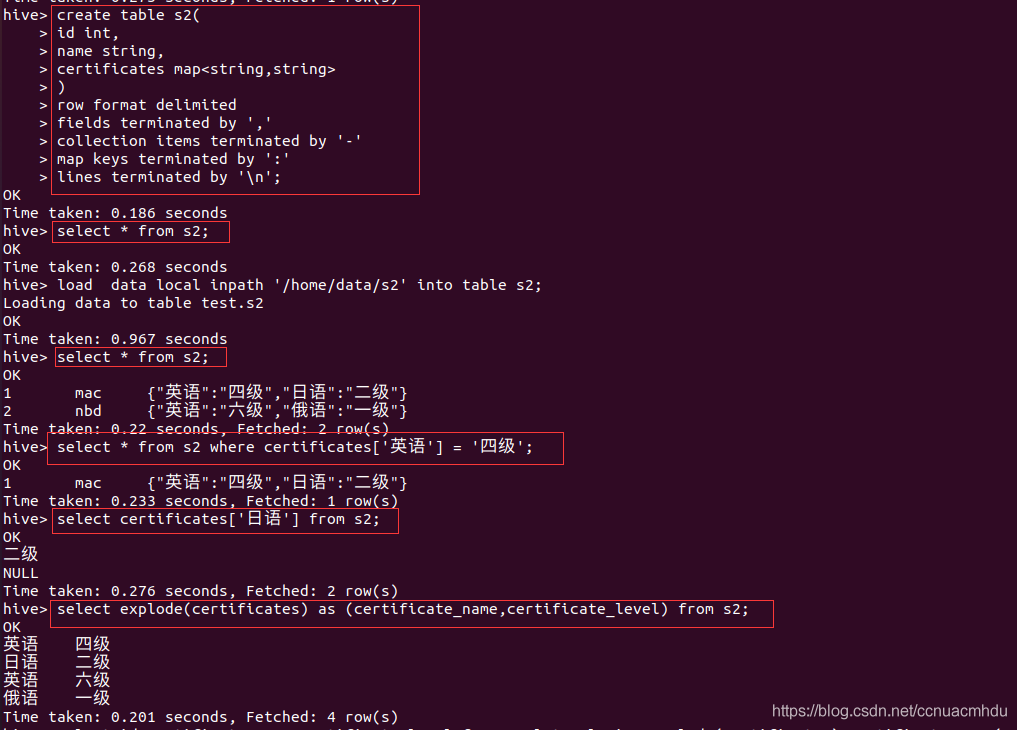

struct
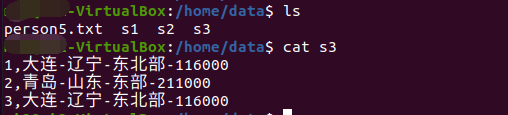
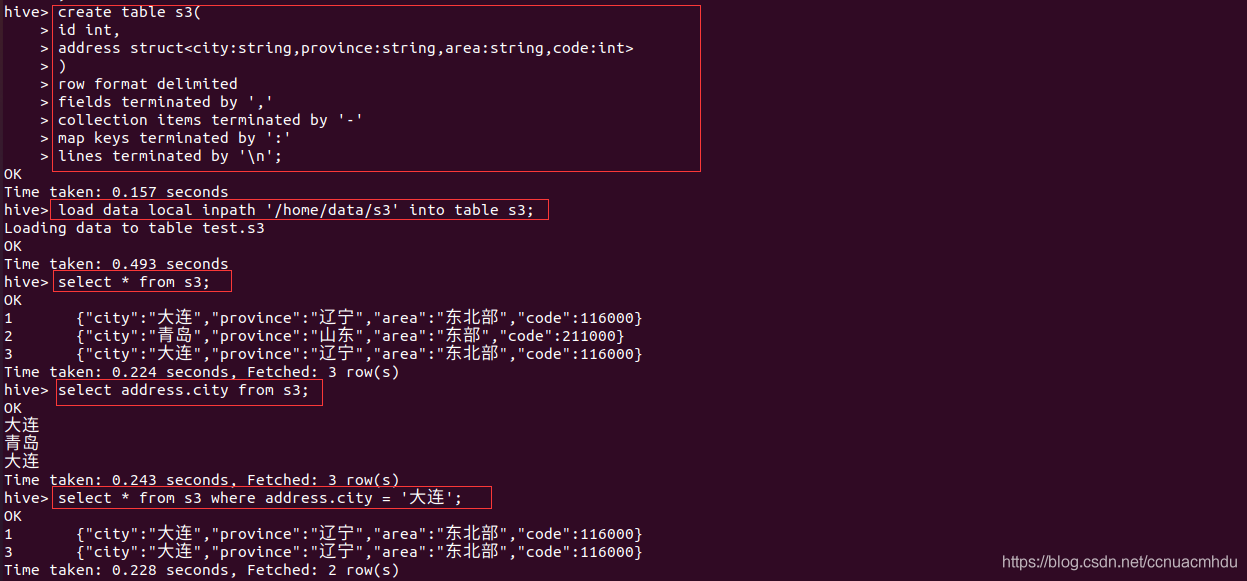
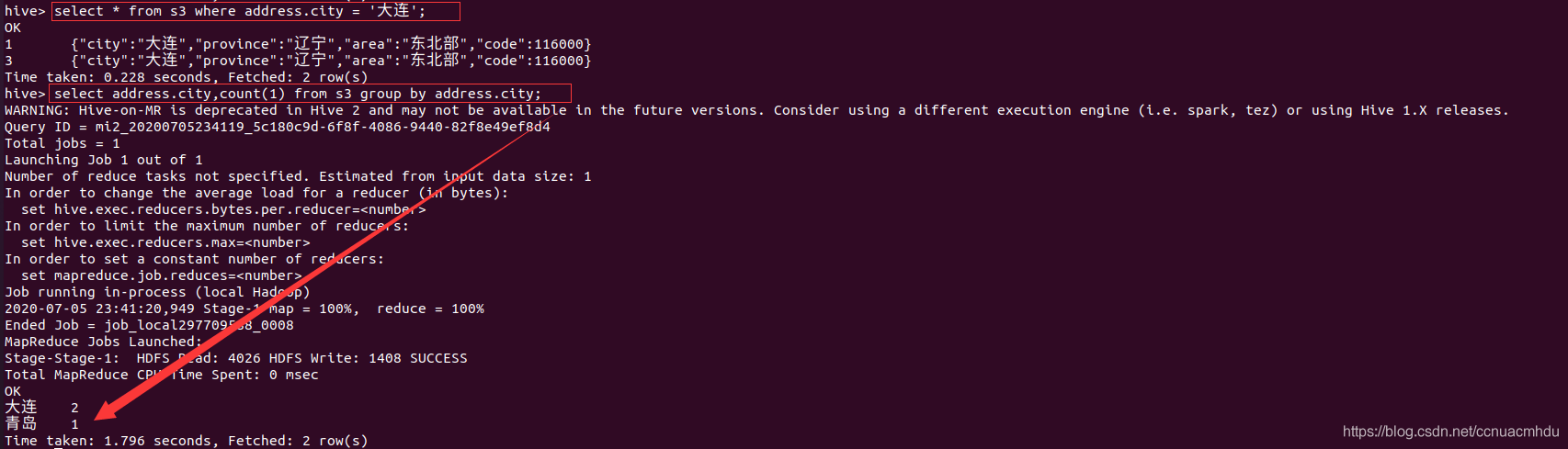
分区
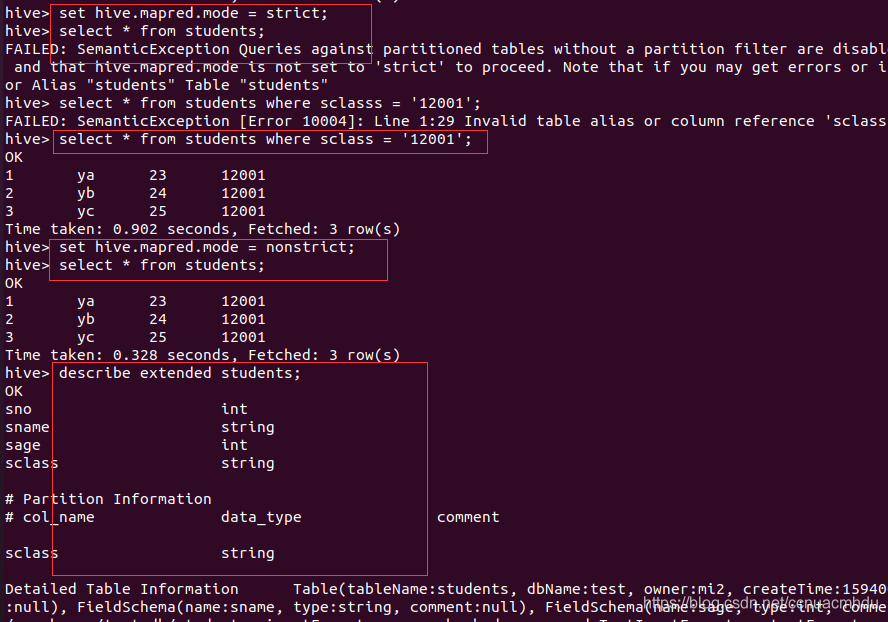
只需要查询一些分区就可以的话,就不用全表扫描,节省时间。
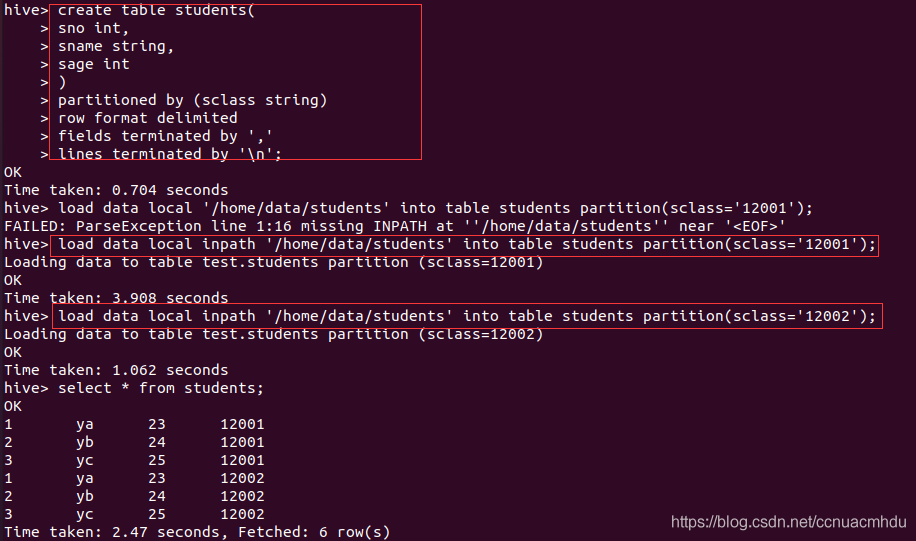
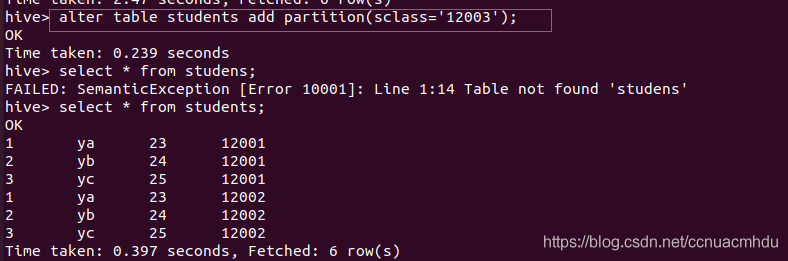
# 添加分区,可在 web 界面(localhost:50070)看到
alter table students add partition(sclass=’12003′);
# 删除分区,会删除该分区下所有数据
alter table students drop partition(sclass=’12002′);
7. Xshell
// 现在服务器安装 sshd 并启动
sudo apt-get install openssh-server
sudo /etc/init.d/ssh start
// 如果有输出 sshd 证明已经开启 ssh 服务
ps -ef | grep sshd
(远程登录工具除了 Xshell 还有 SecureCRT)
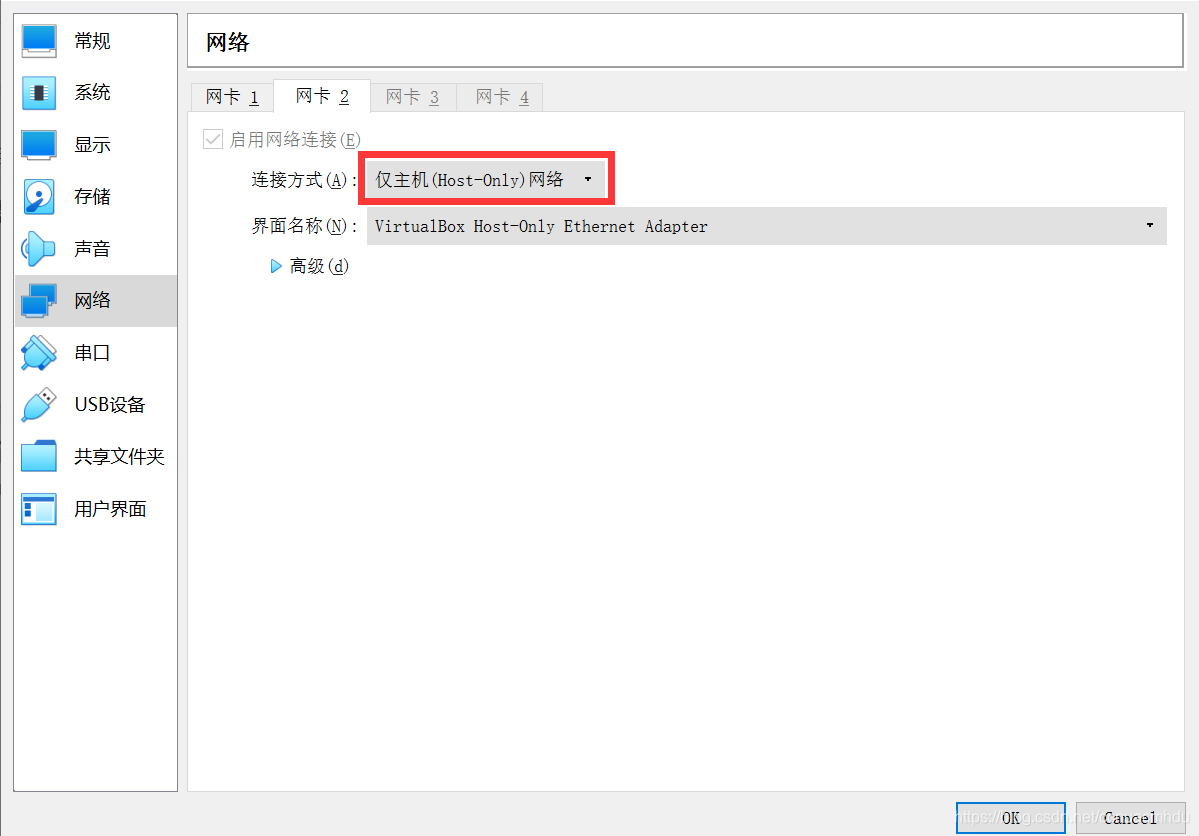
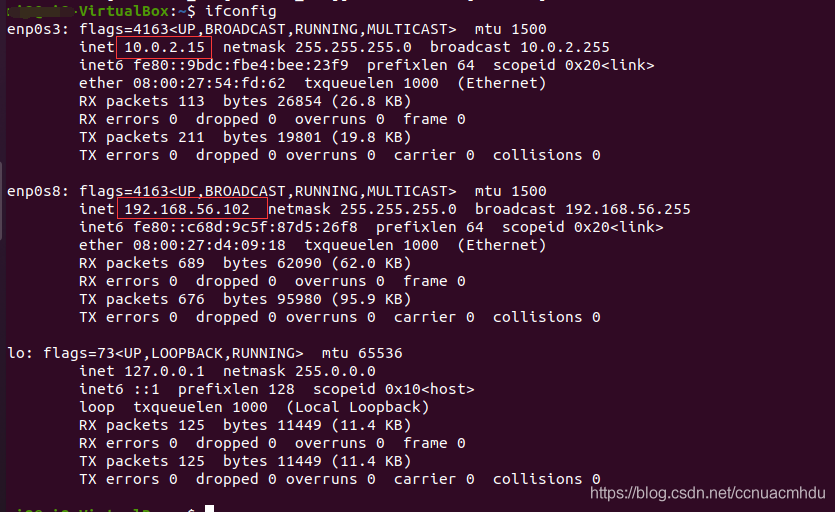
在 Windows 上下载安装 Xshell,然后在 Ubuntu 中 ifconfig,找到 ip,发现 ip 是 10.0.2.15,这和 Windows 的 ip(192.xxx) 明显不在一个网段上,Xshell 肯定访问不到 Ubuntu。解决办法是关机 Ubuntu,在 VirtualBox 中点击设置-网络,如图设置网卡 2。
Ubuntu 开机,再次查看 ip,就有 192.xxx 的了,在 Xshell 中用这个地址访问即可。
另外,rz 是一个常用命令,上传本地文件到远程。
8. 问题
锁异常
Unable to acquire IMPLICIT, SHARED lock mydb after 100 attempts.
Error in acquireLocks…
FAILED: Error in acquiring locks: Locks on the underlying objects cannot be acquired. retry after some time
解决办法是关闭并发,
方式一(hive 命令行中): set hive.support.concurrency=false;
方式二(hive-site.xml 配置):
<property>
<name>hive.support.concurrency</name>
<value>false</value>
<description>
Whether Hive supports concurrency control or not.
A ZooKeeper instance must be up and running when using zookeeper Hive lock manager
</description>
</property>
————————————————
版权声明:本文为CSDN博主「ccnuacmhdu」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/ccnuacmhdu/article/details/107142948