
文章目录
1. 搭建环境
2. 新建WordCount V1.0
3. 坑
1. 搭建环境
搭建 Hadoop集群环境 Hadoop 3.1.2 独立模式,单节点和多节点伪分布式安装与使用
新建环境变量,设置hadoop的用户名,为集群的用户名
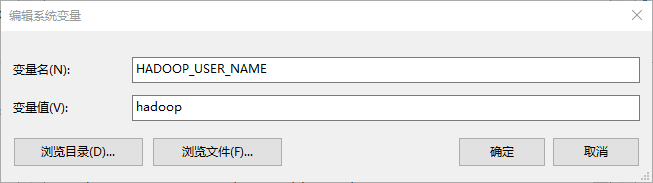
2. 新建WordCount V1.0
添加Maven依赖,虽然hadoop-client中有hadoop-mapreduce-client-jobclient,但不单独添加,IDEA控制台日志不会打印
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>3.1.2</version>
</dependency>
添加log4j.properties到resource文件夹中
log4j.rootLogger=INFO, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.Target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=[%p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%m%n
将Hadoop集群环境中的core-site.xml,hdfs-site.xml,mapred-site.xml,yarn-site.xml添加到resource文件夹中
map
public class WordCountMapper1 extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 读取一行
String line = value.toString();
// 空格分隔
StringTokenizer stringTokenizer = new StringTokenizer(line);
// 循环空格分隔,给每个计数1
while(stringTokenizer.hasMoreTokens()){
word.set(stringTokenizer.nextToken());
context.write(word, one);
}
}
}
reduce
public class WordCountReducer1 extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// 根据key对values计数
int sum = 0;
for(IntWritable intWritable : values){
sum += intWritable.get();
}
result.set(sum);
context.write(key, result);
}
}
WordCount V1.0,需要添加设置用户可以跨平台提交和需要执行jar的路径,即Maven的Package命令生成的该jar的路径
public class WordCount1 {
public static void main( String[] args ) {
// 读取hdfs-site.xml,core-site.xml
Configuration conf = new Configuration();
// 设置用户可以跨平台提交,否则提交成功但是执行失败
conf.set(“mapreduce.app-submission.cross-platform”,”true”);
try{
Job job = Job.getInstance(conf,”WordCount V1.0″);
job.setJarByClass(WordCount1.class);
// 设置需要执行jar的路径,下面根据Maven的Package命令生成的jar路径
job.setJar(“E:\\IDEA_workspace\\mapreduce-test\\target\\mapreduce-test-1.0-SNAPSHOT.jar”);
job.setMapperClass(WordCountMapper1.class);
job.setCombinerClass(WordCountReducer1.class);
job.setReducerClass(WordCountReducer1.class);
// job 输出key value 类型,mapper和reducer类型相同可用
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// hdfs路径
FileInputFormat.addInputPath(job, new Path(“/hdfsTest/input”));
FileOutputFormat.setOutputPath(job, new Path(“/hdfsTest/output”));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}catch (Exception e){
e.printStackTrace();
}
}
}
Maven的Clean和Package,再Rebuild Project,运行main函数,查看日志成功打印
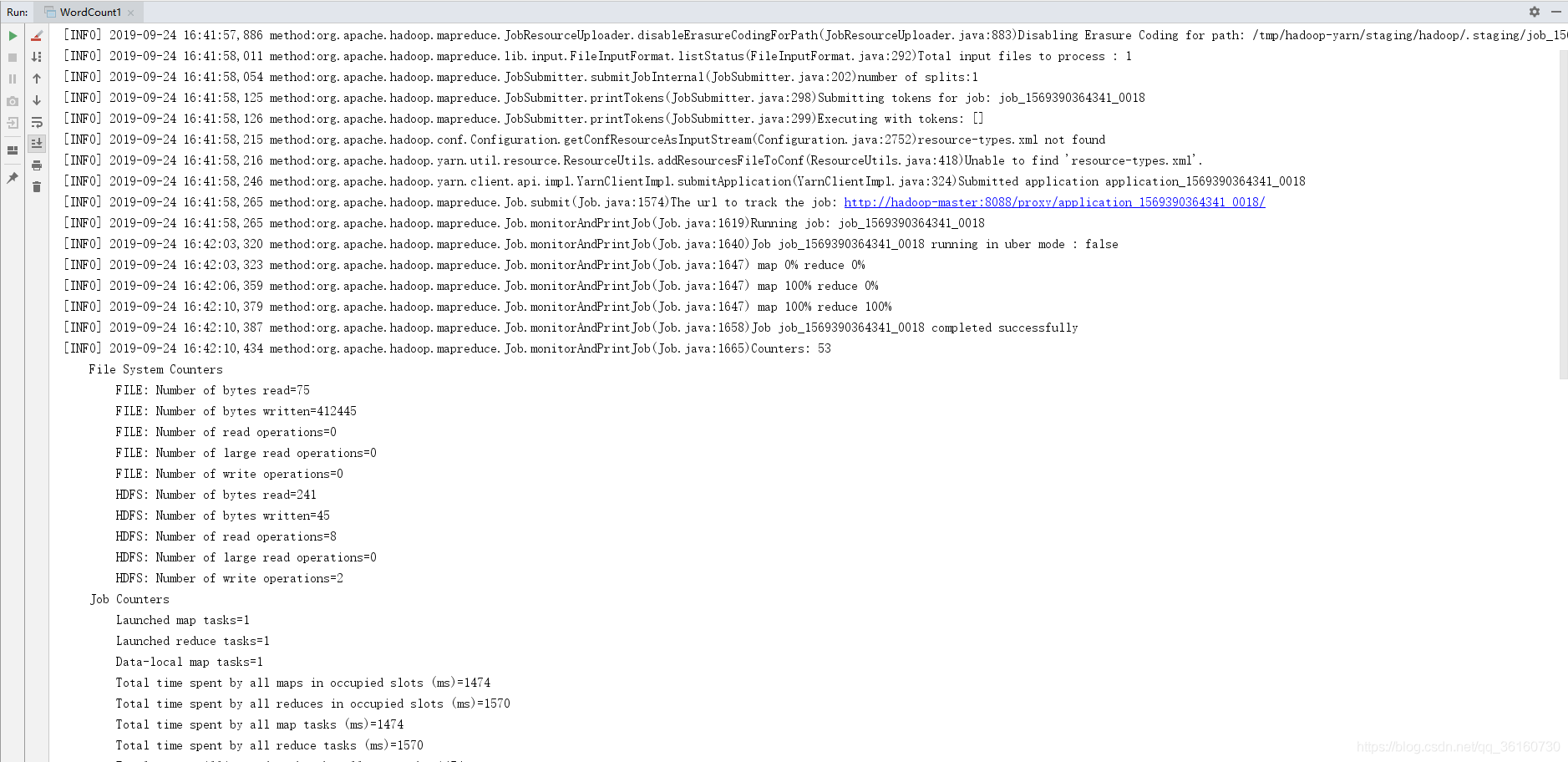
Yarn上也显示运行成功

3. 坑
HDFS和Windows的路径在IDEA上会被识别错误。要Maven进行Clean和Package,然后再Rebuild Project就可以了。
IDEA再Windows上,所以Hadoop会获取Windows上的用户,和集群不同会报错。可以在Windows中添加环境变量,或者在hdfs-site.xml设置权限不可用。
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
需要设置跨平台。可直接在代码中设置,或者在mapred-site.xml设置跨平台。
<property>
<name>mapreduce.app-submission.cross-platform</name>
<value>true</value>
</property>
参考:
本地idea开发mapreduce程序提交到远程hadoop集群执行
Exception message: /bin/bash: line 0: fg: no job control
————————————————
版权声明:本文为CSDN博主「shpunishment」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_36160730/article/details/101292584