
我们在sqoop抽取数据,肯定会 遇到这么个场景,我们肯定会用到一个调度工具来执行sqoop脚本,这时我们如果想在别的客户端也能调用该sqoop脚本,那么我们就需要使用sqoop提供的metastore,metastore它本质是一个hsql内存级数据库,sqoop通过它达到几个客户端共享sqoop脚本的信息,从而使别的客户端也能调用除自己本身创建的sqoop脚本。
在使用metastore之前,我们需要选择一台机器放置metastore,比如我们选择master机器
打开master机器的sqoop-site.xml文件。 cd $SQOOP_HOME/conf/sqoop-site.xml 加入下面的配置
<property>
<name>sqoop.metastore.server.location</name>
<!–数据存放的目录–>
<value>/usr/local/sqoop/tmp/sqoop-metastore/shared.db</value>
<description>Path to the shared metastore database files.
If this is not set, it will be placed in ~/.sqoop/.
</description>
</property>
<property>
<name>sqoop.metastore.server.port</name>
<!–client访问的端口–>
<value>16000</value>
<description>Port that this metastore should listen on.
</description>
</property>
然后再在其他机器的sqoop-site.xml文件加入下面的配置
<property>
<name>sqoop.metastore.client.autoconnect.url</name>
<value>jdbc:hsqldb:hsql://master:16000/sqoop</value>
</property>
最后在启动master的metastore sqoop metastore &,启动成功后,我们能通过jps命令看到一个sqoop应用已经启动

之后我们就是创建一个sqoop job并将其保存进metastore里面。
创建之前我们先在mysql库里面建一张测试表
CREATE TABLE `customer` (
`customer_number` int(11) NOT NULL AUTO_INCREMENT COMMENT ‘客户编号,主键’ ,
`customer_name` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT ‘客户名称’ ,
`customer_street_address` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT ‘客户住址’ ,
`customer_zip_code` int(11) NULL DEFAULT NULL COMMENT ‘邮编’ ,
`customer_city` varchar(30) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT ‘所在城市’ ,
`customer_state` varchar(2) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT ‘所在省份’ ,
`times` timestamp NULL DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP ,
PRIMARY KEY (`customer_number`)
)
ENGINE=MyISAM
DEFAULT CHARACTER SET=utf8 COLLATE=utf8_general_ci
AUTO_INCREMENT=9
CHECKSUM=0
ROW_FORMAT=DYNAMIC
DELAY_KEY_WRITE=0
;
INSERT INTO `customer` VALUES (1, ‘really large customers’, ‘7500 louise dr.’, 17050, ‘mechanicsburg’, ‘pa’, ‘2018-10-10 14:48:29’);
INSERT INTO `customer` VALUES (2, ‘small stores’, ‘2500 woodland st.’, 17055, ‘pittsburgh’, ‘pa’, ‘2018-10-10 13:48:35’);
INSERT INTO `customer` VALUES (3, ‘medium retailers’, ‘1111 ritter rd.’, 17055, ‘pittsburgh’, ‘pa’, ‘2018-10-10 10:48:40’);
INSERT INTO `customer` VALUES (4, ‘good companies’, ‘9500 scott st.’, 17050, ‘mechanicsburg’, ‘pa’, ‘2018-10-6 12:48:48’);
INSERT INTO `customer` VALUES (5, ‘wonderful shops’, ‘3333 rossmoyne rd.’, 17050, ‘mechanicsburg’, ‘pa’, ‘2018-10-10 17:48:55’);
INSERT INTO `customer` VALUES (6, ‘loyal clients’, ‘7070 ritter rd.’, 17055, ‘pittsburgh’, ‘pa’, ‘2018-10-2 14:49:00’);
INSERT INTO `customer` VALUES (7, ‘distinguished partners’, ‘9999 scott st.’, 17050, ‘mechanicsburg’, ‘pa’, ‘2018-10-8 14:49:06’);
编写sqoop脚本
[hdfs@master root]$ sqoop job –create customertest –meta-connect jdbc:hsqldb:hsql://master:16000/sqoop — import –connect jdbc:mysql://hostname:3306/test –query “select * from customer where \$CONDITIONS” –username root –password root –target-dir /data/customer –check-column customer_number –incremental append –last-value 1 -m 1
该sqoop脚本我是采用append的方式 来处理增量数据,每次获得增量数据,我直接另外生成一个小文件保存下来,如果是使用lastModify ,那么增量数据它会根据和并列合并到一个文件里面中。
append
–incremental append 基于递增列的增量导入(将递增列值大于阈值的所有数据增量导入Hadoop)
–check-column 递增列
–last-value 阈值(int)
lastmodified
–incremental lastmodified 基于时间列的增量导入(将时间列大于等于阈值的所有数据增量导入Hadoop)
–check-column 递增列
–last-value 阈值(int)
–merge-key 合并列(主键,合并键值相同的记录)
如果你是lastmodified,那么就必须有个合并列,同时如果操作的文件比较大,那么使用lastmodified就有点慢了,使用append也有个坏处,如果小文件过多了,会影响外部表读取数据的数据,所以这个都大家自己去掌握吧。
之后我们使用sqoop job -list来查看创建的job,我们当时是在master机器上创建的,现在我们可以在segment01机器来查看 我们之前创建的job
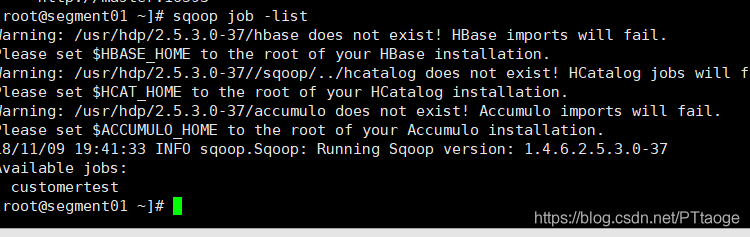
最后在执行这个job

因为我们再每个客户端的配置文件中有配置metastore的属性,所以我们再执行该job时,可以直接省略指定metastore地址的参数。
————————————————
版权声明:本文为CSDN博主「沉默的迷茫」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/pttaoge/article/details/83902233