
前言
Spark 可以跑在很多集群上,比如跑在local上,跑在Standalone上,跑在Apache Mesos上,跑在Hadoop YARN上等等。不管你Spark跑在什么上面,它的代码都是一样的,区别只是–master的时候不一样。其中Spark on YARN是工作中或生产上用的非常多的一种运行模式。
YARN产生背景
以前没有YARN的时候,每个分布式框架都要跑在一个集群上面,比如说Hadoop要跑在一个集群上,Spark用集群的时候跑在standalone上,MPI要跑在一个集群上面,等等。
而且每个分布式框架在各自的集群上跑的时候,都有高峰期低峰期的时候,每个时间点也可能不一样。
这样的话整个集群的资源的利用率非常的低。而且管理起来比较麻烦,因为每个框架都跑在各自的集群上,要去分别管理。
那么能不能进行统一的资源管理和调度?这样YARN就产生了。
那么在YARN上面能跑哪些框架呢?
在YARN上面能运行的框架
有了YARN之后,下图所有的框架都可以跑在YARN集群之上,所有的集群管理都由YARN来负责,可以把YARN理解为:一个操作系统级别的资源管理和调度的框架。
可以在YARN之上跑各种不同的框架,只要它符合YARN的标准就行。这样做的好处,多种计算框架可以共享集群资源,按需分配,你需要多少资源,就取YARN上面申请多少资源,这样可以提升整个资源的利用率。这就是要把各种框架跑在YARN上面的根本原因。
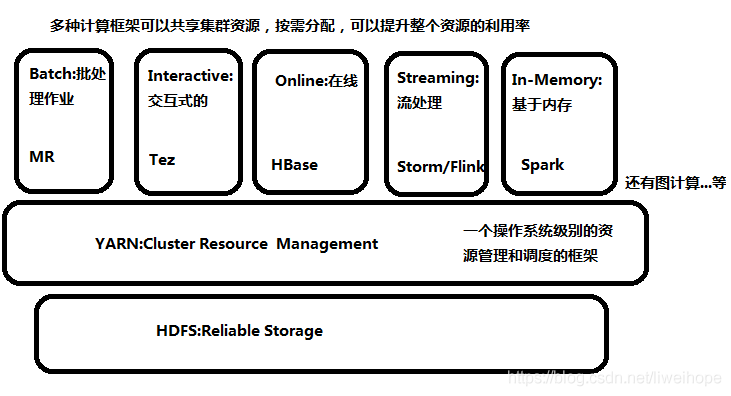
备注:Hive可以跑在MR上面,Tez上面,Spark上面。
YARN架构简单介绍
之前对YARN架构有详细介绍,这里简单说一下。
角色:RM、NM、AM、Container。
面试题必考:各个角色的职责?一个作业挂掉了之后,它怎么重试的,重试的机制?YARN的执行流程?
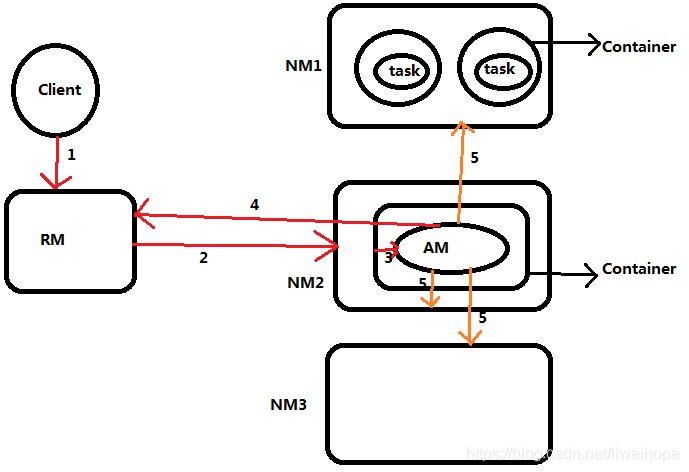
1.client(比如spark)提交一个作业到RM上;
2.RM会找一个NM,并在上面启动一个Container;
3.在Container里面跑AM(作业的主程序);
4.一个作业如果要跑的话要申请资源的,所以AM要到RM上面去申请资源。假如说现在拿到了资源:可以在三个NM上面分别启动Container。
5.拿到了资源列表后,去三个NM上面启动分别启动Container来运行task。
上面是一个通用的执行流程。
对于MR来说,这个task是map task或者reduce task;对于Spark来说,这个task就是executor。
如果是MR的话,那么AM就是MapReduce的Application Master主程序(main函数驱动程序),如果是Spark的话就是Spark的的Application Master主程序(main函数驱动程序)。
Spark on Yarn 概述
直接上图:
关于之前讲的Spark的核心概念:
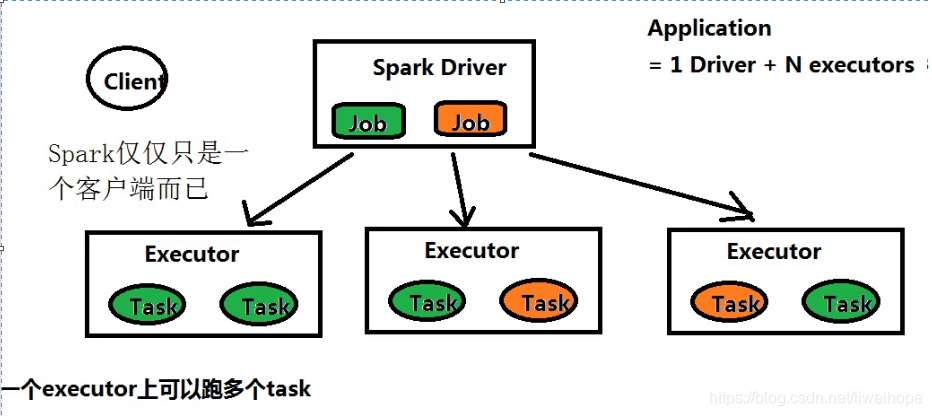
一个Spark应用程序包含一个driver和多个executor。
Driver program是一个进程,它运行应用程序application里面的main()函数,并在main函数里面创建SparkContext。在main函数里面创建了一堆RDD,遇到action的时候会触发job,所以程序会有很多job。
job:由Spark action触发的由多个tasks组成的并行计算。当一个Spark action(如save, collect)被触发,一个包含很多个tasks的并行计算的job将会生成。
每个job被切分成小的任务集,这些小的任务集叫做stages。
task是被发送给一个executor的最小工作单元。每个executor上面可以跑多个task。
Executor:在worker node上启动应用程序的进程,这个进程可以运行多个任务并将数据保存在内存或磁盘存储中。每个Spark应用程序都有它自己的一组executors。executor运行在Container里面。
executor是进程级别,一个进程上面可以并行的跑多个线程的,所以每个executor上面可以跑多个task。
MapReduce和Spark一个本质的区别:
在MapReduce里,每一个task都在它自己的进程里,map对应maptask,reduce对应reducetask,这些都是进程,当一个task完成(maptask或者reducetask)后,这个task进程就结束了。
但是在Spark里面是不一样的,在Spark里面,它的task能够并发的运行在一个进程里,就是说一个进程里面可以运行多个task,而且这个进程会在Spark Application的整个生命周期一直存在,Spark Application是包含一个driver和多个executor的,即使你的作业不再运行了,job运行完了,没有作业在running,它的executor还是一直在的,
对比MapReduce和Spark可知,MapReduce是基于进程的base-process,Spark是基于线程的base-thread。
这样的话,Spark带来的好处就是:
如果是MR的话,你跑task的进程资源都要去申请,用完之后就销毁;但是Spark的话,只要一开始拿到了这些进程资源,后面所有的作业,不需要申请资源,就可以直接快速的启动,是非常的快。用内存的方式进行计算。
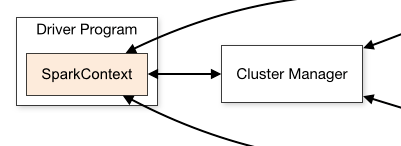
当Spark Application去运行的时候,第一步是向Cluster Manager申请资源。
Spark 可以跑在local、Standalone、Apache Mesos、YARN、K8S上。
Cluster Manager可以适配以上各种模式,是Pluggable可插拔的。
ApplicationMaster:AM
每一个YARN上面的Application都有一个AM,这个AM进程,是在第一个Container里运行的,就是说第一个Container就是来运行AM的,AM去和RM互相通信请求资源,然后拿到资源后告诉NM,让NM启动其它的Container,给我们的进程使用,比如去跑executor。
在YARN里面,没有worker Node概念的,因为在YARN里面,executor是运行在container里面的,worker概念在standalone存在的。executor是在Container里运行的,所以Container的内存的设置要大于executor的内存的,不然跑不起来的。
Spark on yarn模式下,spark仅仅是一个客户端而已,生产中只需要在有gateway权限机器上直接解压部署spark即可,非常的方便,并不需要装一个集群。
Spark on Yarn
如何提交Spark应用程序,之前已经讲过,官网也有:
http://spark.apache.org/docs/latest/submitting-applications.html
Spark Running on Yarn看官网:
http://spark.apache.org/docs/latest/running-on-yarn.html
支持YARN上运行spark是在版本Spark 0.6.0上添加的,并在后续版本中进行了一些改善。
YARN上面启动Spark–理论
确保HADOOP_CONF_DIR或YARN_CONF_DIR指向包含hadoop集群配置文件的文件夹。这些配置用来写数据到hdfs,连接到YARN的resourceManager。(就是说要在配置文件中配置一下,告诉Spark,你要跑在YARN上面,怎么连接到上面等)。此目录中包含的配置将分发到YARN群集,以便应用程序使用的所有容器都使用相同的配置。(比如说,你启动了后,会有很多executor,那么这些executor的配置都是一样的,一样是因为读取的都是相同的文件配置)。如果配置引用了不受YARN管理的Java系统属性或环境变量,那么也应该在Spark应用程序的配置(driver,executors和AM在客户端模式下运行时)中进行设置。
(举例:export HADOOP_CONF_DIR=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/)
There are two deploy modes that can be used to launch Spark applications on YARN. In cluster mode, the Spark driver runs inside an application master process which is managed by YARN on the cluster, and the client can go away after initiating the application. In client mode, the driver runs in the client process, and the application master is only used for requesting resources from YARN.
有两种模式可以在YARN上启动Spark 应用。在集群模式下,Spark驱动程序运行在由集群上的YARN管理的application master进程(AM进程)内部,客户端可以在启动应用程序后关闭。在客户端模式下,驱动程序在客户端进程中运行, application master仅用于从YARN请求资源,客户端是不能关闭的,关掉的话作业就会挂掉。
Unlike other cluster managers supported by Spark in which the master’s address is specified in the –master parameter, in YARN mode the ResourceManager’s address is picked up from the Hadoop configuration. Thus, the –master parameter is yarn.
与Spark支持的其他集群管理器不同比如Spark standalone和Mesos模式,主节点地址在–master参数中指定,在YARN模式下,ResourceManager的地址从Hadoop配置中提取。因此,–master的参数是yarn。
To launch a Spark application in cluster mode:
$ ./bin/spark-submit –class path.to.your.Class –master yarn –deploy-mode cluster [options] <app jar> [app options]
For example:
$ ./bin/spark-submit –class org.apache.spark.examples.SparkPi \
–master yarn \
–deploy-mode cluster \
–driver-memory 4g \
–executor-memory 2g \
–executor-cores 1 \
–queue thequeue \
examples/jars/spark-examples*.jar \
10
以上启动了运行默认Application Master的YARN客户端程序。SparkPi 将作为Application Master的一个子线程运行。客户端将定期轮询Application Master的状态更新并将其显示在控制台中。一旦你的应用结束运行,客户端将退出。
To launch a Spark application in client mode, do the same, but replace cluster with client. The following shows how you can run spark-shell in client mode:
$ ./bin/spark-shell –master yarn –deploy-mode client
–deploy-mode client不写的话默认就是client
YARN上面启动Spark–测试
在我自己的云主机上(4G内存,2个core)
先执行:export HADOOP_CONF_DIR=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/
运行命令:
spark-shell –master yarn –deploy-mode client
发现报错,修改下,把executor改成1个,内存改小一些,运行下面这个命令:
spark-shell –master yarn –deploy-mode client \
–executor-memory 500M \
–num-executors 1
还是报错,如下。一直没有解决,可能是云主机资源太少了的缘故。跑不起来。待解决。。。。。。
ERROR YarnClientSchedulerBackend: The YARN application has already ended! It might have been killed or the Application Master may have failed to start. Check the YARN application logs for more details.
ERROR SparkContext: Error initializing SparkContext.
org.apache.spark.SparkException: Application application_1559720994730_0007 failed 2 times due to AM Container for appattempt_1559720994730_0007_000002 exited with exitCode: 1
For more detailed output, check application tracking page:http://hadoop001:18088/proxy/application_1559720994730_0007/Then, click on links to logs of each attempt.
Diagnostics: Exception from container-launch.
Container id: container_1559720994730_0007_02_000001
Exit code: 1
Stack trace: ExitCodeException exitCode=1:
…..
org.apache.spark.SparkException: Application application_1559720994730_0007 failed 2 times due to AM Container for appattempt_1559720994730_0007_000002 exited with exitCode: 1
….
Container exited with a non-zero exit code 1
Failing this attempt. Failing the application.
…..
如果跑起来之后,可以通过web界面去看相应的job等等,上面有很多信息。
比如:一个job下面有多个stage,一个stage下面有多个task。
举例:
//在spark-shell上执行这个命令:
sc.textFile(“hdfs://文件路径”).flatMap(_.split(“\t”).map((_,1)).reduceByKey(_+_).collect
然后可以去界面上看DAG图:
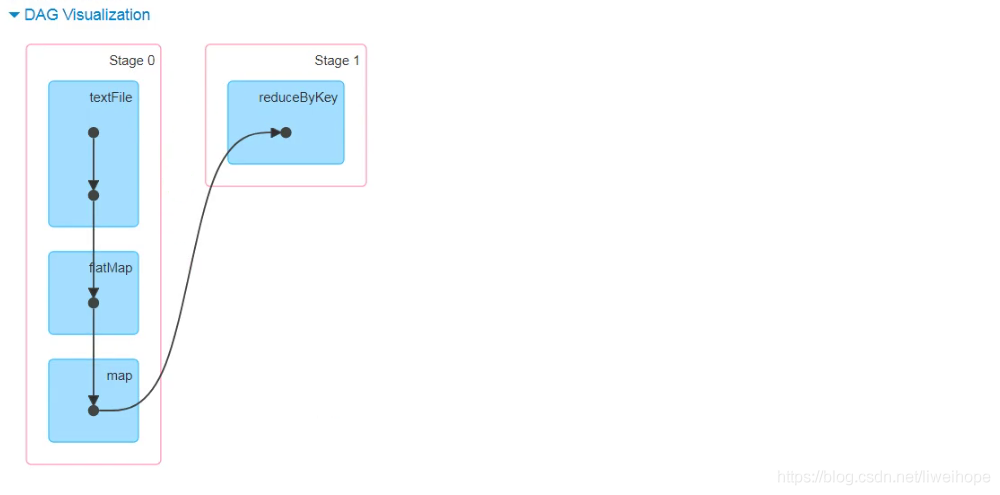
可以看出,collect是一个action,遇到collect的时候触发了这个job;reduceByKey含有shuffle,遇到reduceByKey的时候拆分成两个stage。
然后deploy-mode为 cluster来启动,报错:
[hadoop@hadoop001 ~]$ spark-shell –master yarn –deploy-mode cluster
Exception in thread “main” org.apache.spark.SparkException: Cluster deploy mode is not applicable to Spark shells.
at org.apache.spark.deploy.SparkSubmit.error(SparkSubmit.scala:857)
at org.apache.spark.deploy.SparkSubmit.prepareSubmitEnvironment(SparkSubmit.scala:292)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:143)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:924)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:933)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
[hadoop@hadoop001 ~]$
之前在yarn的运行架构的时候,提到过:由于driver是在集群上调度各个任务的,所以它应该靠近工作节点运行,最好是在同一局域网上运行。如果你想发送请求给远端的集群,最好向驱动程序打开RPC并让它从附近提交操作,而不是远离工作节点运行驱动程序。
所以把driver运行在集群里面,这样driver靠近工作节点(executor节点)运行,性能会更好一点。
但是,如果driver运行在本地local,它的日志就在本地,但是如果运行在集群里面,不知道AM运行在哪个节点上,日志不知道在哪里,你需要怎么看日志?
可通过yarn logs -applicationId 命令查询yarn上作业日志。
Spark Properties 属性
Spark的属性有:
spark.yarn.am.memory、spark.yarn.max.executor.failures、spark.executor.instances、spark.yarn.am.cores等等
这些都有默认值,也都是可以调的。
当这样启动spark-shell的时候:
[hadoop@hadoop001 ~]$ spark-shell –master yarn –deploy-mode client
WARN NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
Setting default log level to “WARN”.
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
WARN Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
。。。。。
里面的这个:
Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
spark.yarn.jars和spark.yarn.archive没有被设置,会把SPARK_HOME下面的这些东西打个包上传到HDFS上面去,这个过程是非常耗性能的。
看一下SPARK_HOME下面,jars和conf路径下面有很多东西,如果打包上传到HDFS上面肯定要耗性能的。
可以通过下面这些参数进行设置,不让它上传(你可以自己先上传到HDFS上面去)
spark.yarn.dist.archives
spark.yarn.dist.files
spark.yarn.dist.jars
这个在生产上很有用的。
spark on yarn总结:
1)如果是local模式,driver跑在本地,driver调度task,把task任务发送给executor,如果是cluster模式,driver跑在集群里。
2)如果是local模式,客户端不可以在启动应用程序后关闭。如果是cluster模式,客户端可以在启动应用程序后关闭
2)AM:Application Master
本地local模式:AM仅仅用于申请资源
cluster集群模式:AM不仅仅用于申请资源,还有task的调度
(cluster集群模式:driver跑在AM进程里面,driver的对task的调度就由AM来执行了)
什么时候选择client,什么什么选择cluster?都可以的,你可以选择cluster,但是很多场景都是选择client模式的。
————————————————
版权声明:本文为CSDN博主「liweihope」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/liweihope/article/details/91358144