windows环境
IntelliJ IDEA
JDK1.8
hadoop-2.8.5.tar.gz
从官网上下载解压配置JDK,
Hadoop https://hadoop.apache.org/releases.html 下载2.8.5版本Binary download并解压到自己喜欢的目录下。
配置windows环境变量
Java环境变量就不写了,都应该知道
变量名:HADOOP_HOME 路径:E:\hadoop\hadoop-2.8.5
变量名:HADOOP_BIN_PATH 路径:%HADOOP_HOME%\bin
变量名:HADOOP_PREFIX 路径:E:\hadoop\hadoop-2.8.5
变量名:HADOOP_USER_NAME 路径:hadoop (根据安装hadoop时配置的用户名)
变量名:Path 追加:%HADOOP_HOME%\bin;%HADOOP_HOME%\sbin; (注意分号)
配置内网映射
修改C:\Windows\System32\drivers\etc\hosts文件,添加集群里/etc/hosts相同的主机映射(根据自己实际安装的集群地址)
192.168.189.130 hadoop1
192.168.189.131 hadoop2
192.168.189.132 hadoop3
项目搭建
IDEA创建Maven项目,项目名hadoop-demo,这里用的Spring Boot的方式。设置好jdk版本,添加maven依赖:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.4</version>
</dependency>
项目结构
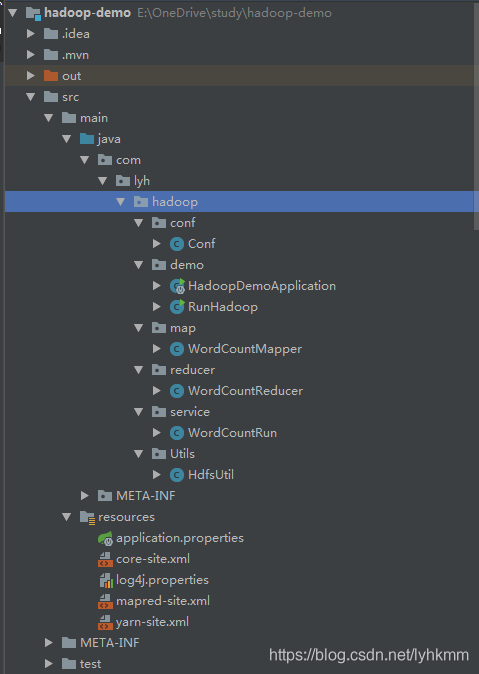
配置项目配置文件
将hadoop集群中的配置文件:core-site.xml、mapred-site.xml、yarn-site.xml、log4j.properties复制到resource目录下。
根据自己集群实际环境配置,可以查看git上面源码
创建待处理的文档
在E:\hadoop\upload\新建word.txt,内容如下(随便找几段内容就行):
The Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing.
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
1
2
HDFS操作工具类HdfsUtil .class
import com.lyh.hadoop.conf.Conf;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.log4j.Logger;
import java.io.*;
public class HdfsUtil {
private static Logger logger = Logger.getLogger("this.class");
public static FileSystem getFiles() {
//获得连接配置
Configuration conf = Conf.get();
FileSystem fs = null;
try {
fs = FileSystem.get(conf);
} catch (IOException e) {
logger.error("配置连接失败"+e.getMessage());
}
return fs;
}
/**
* 创建文件夹
*/
public static void mkdirFolder(String folderPath) {
try {
FileSystem fs = getFiles();
fs.mkdirs(new Path(folderPath));
logger.info("创建文件夹成功:"+folderPath);
} catch (Exception e) {
logger.error("创建失败"+e.getMessage());
}
}
/**
* 上传文件到hdfs
*
*/
public static void uploadFile(String localFolderPath, String fileName, String hdfsFolderPath) {
FileSystem fs = getFiles();
try {
InputStream in = new FileInputStream(localFolderPath + fileName);
OutputStream out = fs.create(new Path(hdfsFolderPath + fileName));
IOUtils.copyBytes(in, out, 4096, true);
logger.info("上传文件成功:"+fileName);
} catch (Exception e) {
logger.error("上传文件失败"+e.getMessage());
}
}
/**
* 从hdfs获取文件
*/
public static void getFileFromHadoop(String downloadPath, String downloadFileName, String savePath) {
FileSystem fs = getFiles();
try {
InputStream in = fs.open(new Path(downloadPath + downloadFileName));
OutputStream out = new FileOutputStream(savePath + downloadFileName);
IOUtils.copyBytes(in, out, 4096, true);
} catch (Exception e) {
logger.error("获取文件失败"+e.getMessage());
}
}
/**
* 删除文件
* delete(path,boolean)
* boolean如果为true,将进行递归删除,子目录及文件都会删除
* false 只删除当前
*/
public static void deleteFile(String deleteFilePath) {
FileSystem fs = getFiles();
//要删除的文件路径
try {
Boolean deleteResult = fs.delete(new Path(deleteFilePath), true);
} catch (Exception e) {
logger.error("删除文件失败"+e.getMessage());
}
}
/**
* 日志打印文件内容
*/
public static void readOutFile(String filePath) {
try {
InputStream inputStream = getFiles().open(new Path(filePath));
BufferedReader bf = new BufferedReader(new InputStreamReader(inputStream, "GB2312"));//防止中文乱码
String line = null;
while ((line = bf.readLine()) != null) {
logger.info(line);
}
} catch (Exception e) {
logger.error(e.getMessage(), e);
}
}
}
Mapper.class
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* LongWritable 行号 类型
* Text 输入的value 类型
* Text 输出的key 类型
* IntWritable 输出的vale类型
*/
public class WordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable> {
/**
* 将文档按照行号转换成map,如(1,'this is first line'),(2,'this is second line')
* 再将(1,'this is first line')转换成('this',1),('is',1),('first',1),('line',1)
* @param key 行号
* @param value 第一行的内容 如 this is first line
* @param context 输出
* @throws IOException 异常
* @throws InterruptedException 异常
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
//规则:以中英文逗号、空格(一个或多个)分割字符串
String regex = ",|,|\\.|\\s+";
String[] words = line.split(regex);
for (String word : words) {
context.write(new Text(word),new IntWritable(1));
}
}
}
Reducer类
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* Text 输入的key的类型
* IntWritable 输入的value的类型
* Text 输出的key类型
* IntWritable 输出的value类型
*/
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
/**
* (1,'this is first line')转换成('this',1),('is',1),('first',1),('line',1)后统计各个单词出事的次数
* @param key 输入map的key
* @param values 输入map的value
* @param context 输出
* @throws IOException 异常
* @throws InterruptedException 异常
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
for (IntWritable value : values) {
count += value.get();
}
context.write(key, new IntWritable((count)));
}
}
WordCountRun.class
import com.lyh.hadoop.Utils.HdfsUtil;
import com.lyh.hadoop.conf.Conf;
import com.lyh.hadoop.map.WordCountMapper;
import com.lyh.hadoop.reducer.WordCountReducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.log4j.Logger;
public class WordCountRun {
private static Logger logger = Logger.getLogger("this.class");
//输入文件路径
static String inPath = "/hadoop_demo/input/words.txt";
//输出文件目录
static String outPath = "/hadoop_demo/output/result/";
public static void Run() {
//创建word_input目录
String folderName = "/hadoop_demo/input";
HdfsUtil.mkdirFolder(folderName);
//创建word_input目录
folderName = "/hadoop_demo/output";
HdfsUtil.mkdirFolder(folderName);
//上传文件
String localPath = "E:\\hadoop\\upload\\";
String fileName = "words.txt";
String hdfsPath = "/hadoop_demo/input/";
HdfsUtil.uploadFile(localPath, fileName, hdfsPath);
try {
//执行
mapReducer();
//成功后下载文件到本地
String downName = "part-r-00000";
String savePath = "E:\\hadoop\\download\\";
//打印内容
HdfsUtil.readOutFile(outPath+downName);
HdfsUtil.getFileFromHadoop(outPath, downName, savePath);
} catch (Exception e) {
logger.error(e.getMessage());
}
}
public static void mapReducer() throws Exception{
//获取连接配置
Configuration conf = Conf.get();
//创建一个job实例
Job job = Job.getInstance(conf,"wordCount");
//设置job的主类
job.setJarByClass(WordCountRun.class);
//设置job的mapper类和reducer类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//设置Mapper的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置Reduce的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置输入和输出路径
FileSystem fs = HdfsUtil.getFiles();
Path inputPath = new Path(inPath);
FileInputFormat.addInputPath(job,inputPath);
Path outputPath = new Path(outPath);
fs.delete(outputPath,true);
FileOutputFormat.setOutputPath(job,outputPath);
job.waitForCompletion(true);
}
}
RunHadoop.class,Main方法
public class RunHadoop {
public static void main(String[] args) {
WordCountRun.Run();
}
}
配置导出jar,IDEA进入配置项目
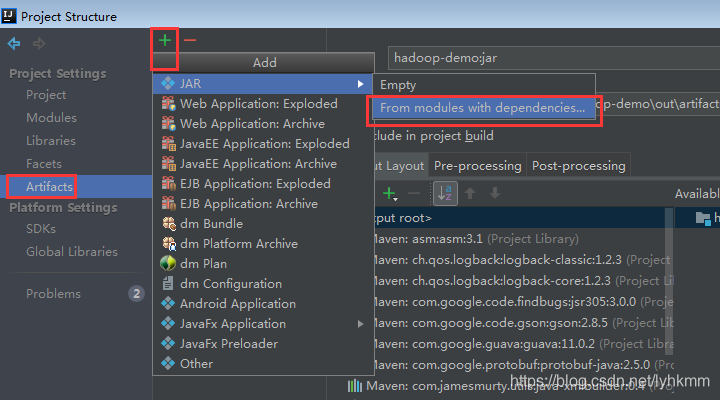
按下图操作

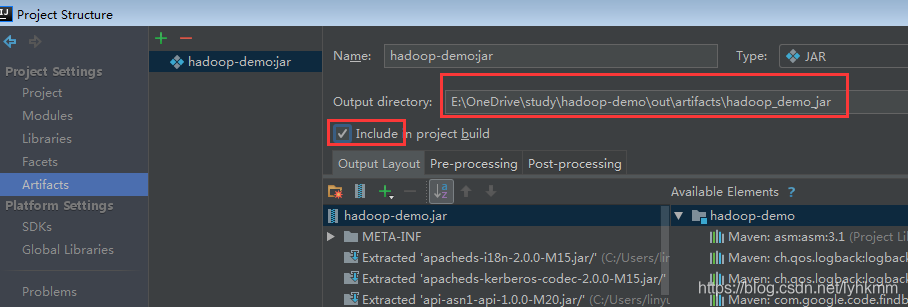
复制导出的路径地址,并且加上生成包的文件名,下一个配置类要用到。
E:\OneDrive\study\hadoop-demo\out\artifacts\hadoop_demo_jar\hadoop-demo.jar
Conf.class(配置与hadoop的连接)
import org.apache.hadoop.conf.Configuration;
public class Conf {
public static Configuration get (){
//hdfs的链接地址
String hdfsUrl = "hdfs://hadoop1:9000";
//hdfs的名字
String hdfsName = "fs.defaultFS";
//jar包文位置(上一个步骤获得的jar路径)
String jarPath = "E:\\OneDrive\\study\\hadoop-demo\\out\\artifacts\\hadoop_demo_jar\\hadoop-demo.jar";
Configuration conf = new Configuration();
conf.set(hdfsName,hdfsUrl);
conf.set("mapreduce.app-submission.cross-platform", "true");
conf.set("mapreduce.job.jar",jarPath);
return conf;
}
}
运行
如遇到程序报错java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries,这是因为windows环境变量不兼容的原因。
解决办法:
下载winutils地址https://github.com/srccodes/hadoop-common-2.2.0-bin下载解压
复制winutils.exe winutils.pdb到之前配置好的hadoop/bin目录下
console输出结果,查看E:\hadoop\download\part-r-00000(部分省略)
Apache 1
Apache™ 1
Hadoop 1
Hadoop® 1
It 1
Rather 1
The 2
a 3
across 1
allows 1
and 2
application 1
at 1
be 1
……
github地址 https://github.com/lyhkmm/hadoop-demo
————————————————
版权声明:本文为CSDN博主「蒙蒙的林先生」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/lyhkmm/article/details/87811177