一、问题背景
美团CRM系统中每天有大量的后台任务需要调度执行,如构建索引、统计报表、周期同步数据等等,要求任务调度系统具备高可用性、负载均衡特性,可以管理并监控任务的执行流程,以保证任务的正确执行。
二、历史方案
美团CRM系统的任务调度模块经历了以下历史方案。
1. Crontab+SQL
每天晚上运行定时任务,通过SQL脚本+crontab方式执行,例如,
#crm
0 2 * * * /xxx/mtcrm/shell/mtcrm_daily_stat.sql //每天凌晨2:00执行统计
30 7 * * * /xxx/mtcrm/shell/mtcrm_data_fix.sql //每天早上7:30执行数据修复
该方案存在以下问题:
- 直接访问数据库,各系统业务接口没有重用。
- 完成复杂业务需求时,会引入过多中间表。
- 业务逻辑计算完全依赖SQL,增大数据库压力。
- 任务失败无法自动恢复。
2. Python+SQL
采用python脚本(多数据源)+SQL方式执行,例如,
def connectCRM():
return MySQLdb.Connection("host1", "uname", "xxx", "crm", 3306, charset="utf8")
def connectTemp():
return MySQLdb.Connection("host1", "uname", "xxx", "temp", 3306, charset="utf8")
该方案存在问题:
- 直接访问数据,需要理解各系统的数据结构,无法满足动态任务问题,各系统业务接口没有重用。
- 无负载均衡。
- 任务失败无法恢复。
- 在JAVA语言开发中出现异构,且很难统一到自动部署系统中。
3. Spring+JDK Timer
该方案使用spring+JDK Timer方式,调用接口完成定时任务,在分布式部署环境下,防止多个节点同时运行任务,需要写死host,控制在一台服务器上执行task。
<bean id="accountStatusTaskScanner" class="xxx.crm.service.impl.AccountStatusTaskScanner" />
<task:scheduler id="taskScheduler" pool-size="5" />
<task:scheduled-tasks scheduler="taskScheduler">
<task:scheduled ref="accountStatusTaskScanner" method="execute" cron="0 0 1 * * ?" />
</task:scheduled-tasks>
该方案较方案1,2有很大改进,但仍存在以下问题:
- 步骤复杂、分散,任务量增大的情况下,很难扩展
- 使用写死服务器Host的方式执行task,存在单点风险,负载均衡手动完成。
- 应用重启,任务无法自动恢复。
CRM系统定时任务走过了很多弯路:定时任务多种实现方式,使配置和代码分散在多处,难以维护和监控;任务执行过程没有保证,没有错误恢复;任务执行异常没有反馈(邮件);没有集群支持、负载均衡。CRM系统需要分布式的任务调度框架,统一解决问题,Java可以使用的任务调度框架有Quartz,Jcrontab,cron4j,我们选择了Quartz。
三、为什么选择Quartz
Quartz是Java领域最著名的开源任务调度工具。Quartz提供了极为广泛的特性如持久化任务,集群和分布式任务等,其特点如下:
- 完全由Java写成,方便集成(Spring)
- 伸缩性
- 负载均衡
- 高可用性
四、Quartz集群部署实践
CRM中Quartz与Spring结合使用,Spring通过提供org.springframework.scheduling.quartz下的封装类对Quartz支持。
Quartz集群部署:
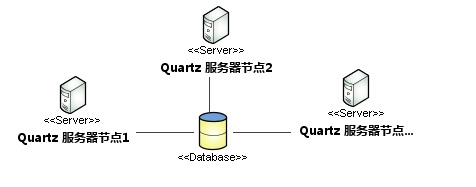
Quartz集群中的每个节点是一个独立的Quartz应用,它又管理着其他的节点。该集群需要分别对每个节点分别启动或停止,不像应用服务器的集群,独立的Quartz节点并不与另一个节点或是管理节点通信。Quartz应用是通过数据库表来感知到另一应用。只有使用持久的JobStore才能完成Quqrtz集群。
基于Spring的集群配置:
<!-- 调度工厂 -->
<bean id="quartzScheduler"
class="org.springframework.scheduling.quartz.SchedulerFactoryBean">
<property name="dataSource" ref="dataSource" />
<property name="quartzProperties">
<props>
<prop key="org.quartz.scheduler.instanceName">CRMscheduler</prop>
<prop key="org.quartz.scheduler.instanceId">AUTO</prop>
<!-- 线程池配置 -->
<prop key="org.quartz.threadPool.class">org.quartz.simpl.SimpleThreadPool</prop>
<prop key="org.quartz.threadPool.threadCount">20</prop>
<prop key="org.quartz.threadPool.threadPriority">5</prop>
<!-- JobStore 配置 -->
<prop key="org.quartz.jobStore.class">org.quartz.impl.jdbcjobstore.JobStoreTX</prop>
<!-- 集群配置 -->
<prop key="org.quartz.jobStore.isClustered">true</prop>
<prop key="org.quartz.jobStore.clusterCheckinInterval">15000</prop>
<prop key="org.quartz.jobStore.maxMisfiresToHandleAtATime">1</prop