
背景
目前美团点评已累计了丰富的线上交易与用户行为数据,为商家赋能需要我们有更强大的专业化数据加工能力,来帮助商家做出正确的决策从而提高用户体验。目前商家端产品在数据应用上主要基于离线数据加工,数据生产调度以“T+1”为主,伴随着越来越深入的精细化运营,实时数据应用诉求逾加强烈。本文将从目前主流实时数据处理引擎的特点和我们面临的问题出发,简单的介绍一下我们是如何搭建实时数据处理系统。
设计框架
目前比较流行的实时处理引擎有 Storm,Spark Streaming,Flink。每个引擎都有各自的特点和应用场景。 下表是对这三个引擎的简单对比:
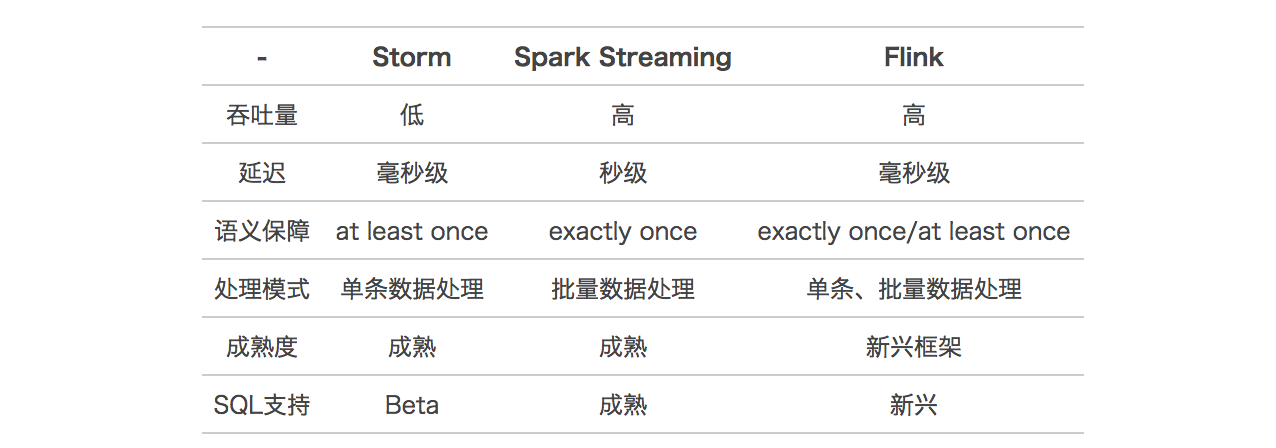
考虑到每个引擎的特点、商家端应用的特点和系统的高可用性,我们最终选择了 Storm 作为本系统的实时处理引擎。
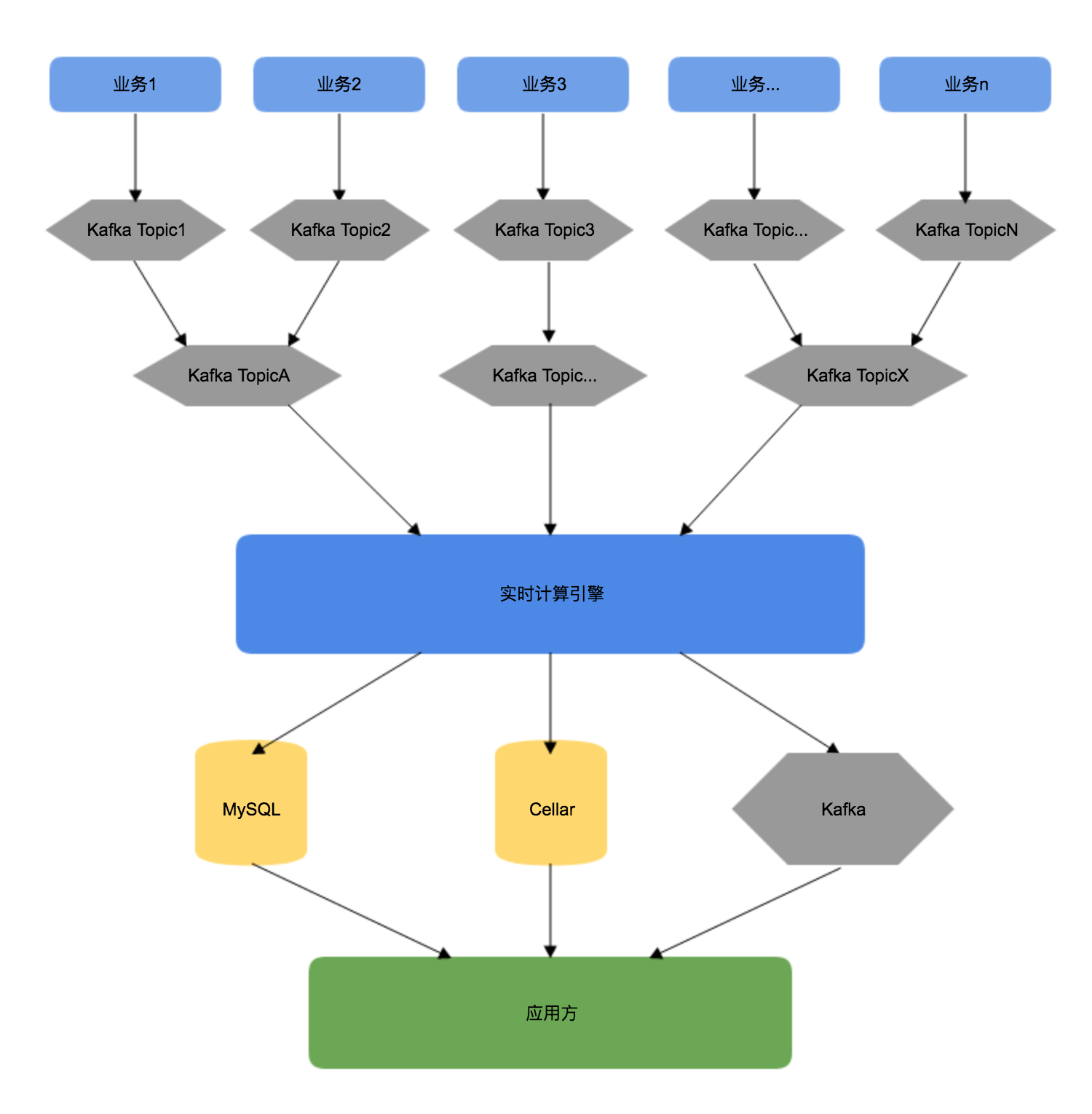
面临的问题
- 数据量的不稳定性,导致对机器需求的不确定性。用户的行为数据会受到时间的影响,比如半夜时刻和用餐高峰时段每分钟产生的数据量有两个数量级的差异。
- 上游数据质量的不确定性。
- 数据计算时,数据的落地点应该放到哪里来保证计算的高效性。
- 如何保证数据在多线程处理时数据计算的正确性。
- 计算好的数据以什么样的方式提供给应用方。
具体的实施方案
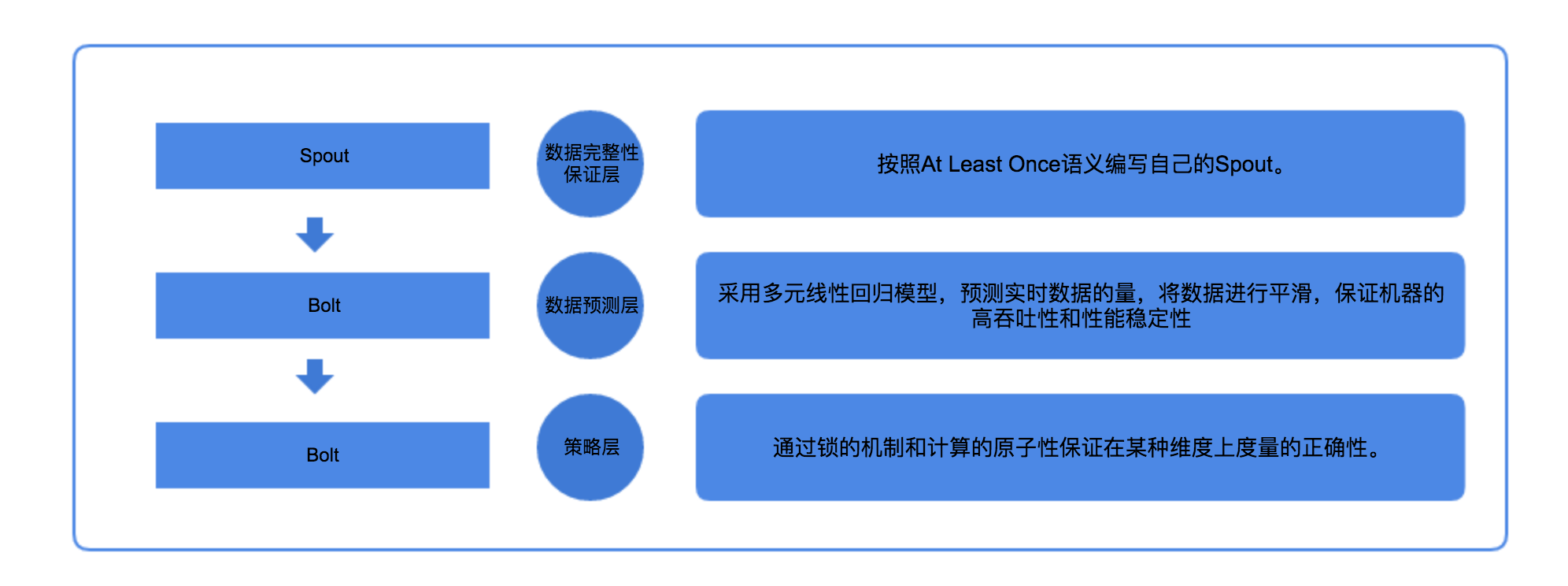
实时摄入数据完整性保障
数据完整性保证层:如何保证数据摄入到计算引擎的完整性呢?正如表格中比较的那样,Storm 框架的语义为 At Least Once,至少摄入一次。这个语义的存在正好保证了数据的完整性,所以只需要根据自己的需求编写 Spout 即可。好消息是我们的技术团队已经开发好了一个满足大多数需求的 Spout,可以直接拿来使用。特别需要注意的一点,在数据处理的过程中需要我们自己来剔除已经处理过的数据,因为 Storm 的语义会可能导致同一条数据摄入两次。灰度发布期间(一周)对数据完整性进行验证,数据完整性为100%。
实时数据平滑处理
数据预测层:实时的数据预测可以帮助我们对到达的数据进行有效的平滑,从而可以减少在某一时刻对集群的压力。 在数据预测方面,我们采用了在数学上比较简单的多元线性回归模型(如果此模型不满足业务需求,可以选用一些更高级别的预测模型),预测下一分钟可能到来的数据的量。在数据延迟可接受的范围内,对数据进行平滑,并完成对数据的计算。通过对该方案的使用,减轻了对集群约33%的压力。具体步骤如下:
- 步骤一:将多个业务的实时数据进行抽象化,转换为(Y_i,X_1𝑖,X_2𝑖,X_3i,… ,X_ni),其中Y_i为在(X_1i…X_ni)属性下的数据量,(X_1i…X_ni)为n个不同的属性,比如时间、业务、用户的性别等等。
- 步骤二:因为考虑到实时数据的特殊性,不同业务的数据量随时间变量基本呈现为M走势,所以为了将非线性走势转换为线性走势,可以将时间段分为4部分,保证在每个时间段内数据的走势为线性走势。同理,如果其他的属性使得走势变为非线性,也可以分段分析。
-
步骤三:将抽象好的数据代入到多元线性回归模型中,其方程组形式为:
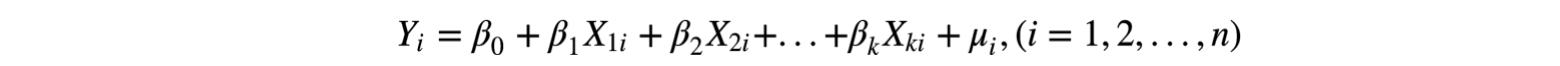
即:
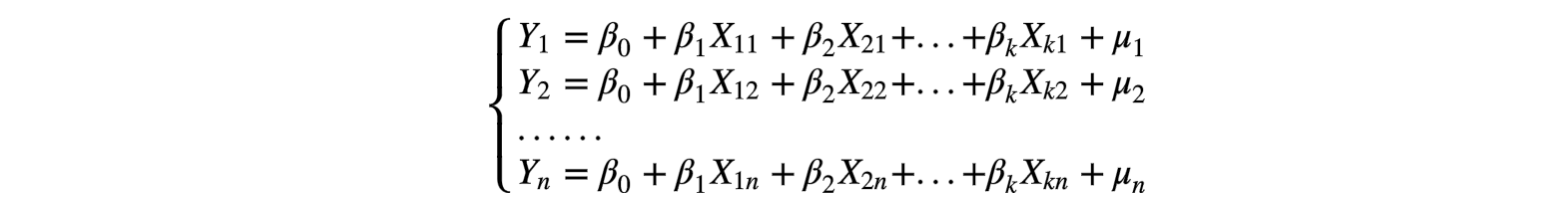
通过对该模型的求解方式求得估计参数,最后得多元线性回归方程。
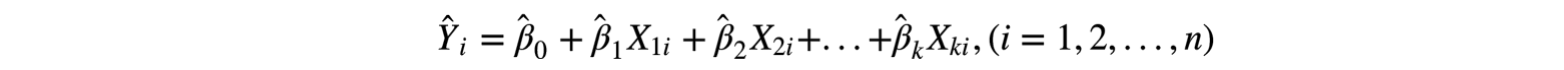
-
步骤四:数据预测完之后通过控制对数据的处理速度,保证在规定的时间内完成对规定数据的计算,减轻对集群的压力。
实时数据计算策略
策略层:Key/Value 模式更适应于实时数据模型,不管是在存储还是计算方面。Cellar(我们内部基于阿里开源的Tair研发的公共KV存储)作为一个分布式的 Key/Value 结构数据的解决方案,可以做到几乎无延迟的进行 IO 操作,并且可以支持高达千万级别的 QPS,更重要的是 Cellar 支持很多原子操作,运用在实时数据计算上是一个不错的选择。所以作为数据的落脚点,本系统选择了Cellar。
但是在数据计算的过程中会遇到一些问题,比如说统计截止到当前时刻入住旅馆的男女比例是多少?很容易就会想到,从 Cellar 中取出截止到当前时刻入住的男生是多少,女生是多少,然后做一个比值就 OK 了。但是本系统是在多线程的环境运行的,如果该时刻有两对夫妇入住了,产生了两笔订单,恰好这两笔订单被两个线程所处理,当线程A将该男士计算到结果中,正要打算将该女士计算到结果中的时候,线程B已经计算完结果了,那么线程B计算出的结果就是2/1,那就出错啦。
所以为了保证数据在多线程处理时数据计算的正确性,我们需要用到分布式锁。实现分布式锁的方式有很多,本文就不赘述了。这里给大家介绍一种更简单快捷的方法。Cellar 中有个 setNx 函数,该函数是原子的,并且是(Set If Not Exists),所以用该函数锁住关键的字段就可以。就上面的例子而言,我们可以锁住该旅馆的唯一 ID 字段,计算完之后 delete 该锁,这样就可以保证了计算的正确性。
另外一个重要的问题是 Cellar 不支持事务,就会导致该计算系统在升级或者重启时会造成少量数据的不准确。为了解决该问题,运用到一种 getset 原子思想的方法。如下:
public void doSomeWork(String input) {
cellar.mapPut("uniq_ID");
cellar.add("uniq_ID_1","some data");
cellar.add("uniq_ID_2","some data again");
....
cellar.mapRemove("uniq_ID");
}
如果上述代码执行到[2..5]某一行时系统重启了,导致后续的操作并没有完成,如何将没有完成的操作添加上去呢?如下:
public void remedySomething() {
map = cellar.mapGetAll();
version = cellar.mapGet("uniq_ID").getVersion();
for (string str : map) {
if (cellar.get(str + "_1").getVersion()!= version) {
cellar.add(str + "_1", "some data");
cellar.mapRemove(str);
}
.......
}
}
正如代码里那样,会有一个容器记录了哪些数据正在被操作,当系统重启的时候,从该容器取出上次未执行完的数据,用 Version(版本号)来记录哪些操作还没有完成,将没有完成的操作补上,这样就可以保证了计算结果的准确性。起初 Version(版本号)被设计出来解决的问题是防止由于数据的并发更新导致的问题。
比如,系统有一个 value 为“a,b,c”,A和B同时get到这个 value。A执行操作,在后面添加一个d,value 为 “a,b,c,d”。B执行操作添加一个e,value为”a,b,c,e”。如果不加控制,无论A和B谁先更新成功,它的更新都会被后到的更新覆盖。Tair 无法解决这个问题,但是引入了version 机制避免这样的问题。还是拿刚才的例子,A和B取到数据,假设版本号为10,A先更新,更新成 功后,value 为”a,b,c,d”,与此同时,版本号会变为11。当B更新时,由于其基于的版本号是10,服务器会拒绝更新,从而避免A的更新被覆盖。B可以选择 get 新版本的 value,然后在其基础上修改,也可以选择强行更新。
将 Version 运用到事务的解决上也算是一种新型的使用。为验证该功能的正确性,灰度发布期间每天不同时段对项目进行杀死并重启,并对数据正确性进行校验,数据的正确性为100%。
实时数据存储
为了契合更多的需求,将数据分为三部分存储。
Kafka:存储稍加工之后的明细数据,方便做更多的扩展。 MySQL:存储中间的计算结果数据,方便计算过程的可视化。 Cellar:存储最终的结果数据,供应用层直接查询使用。
应用案例
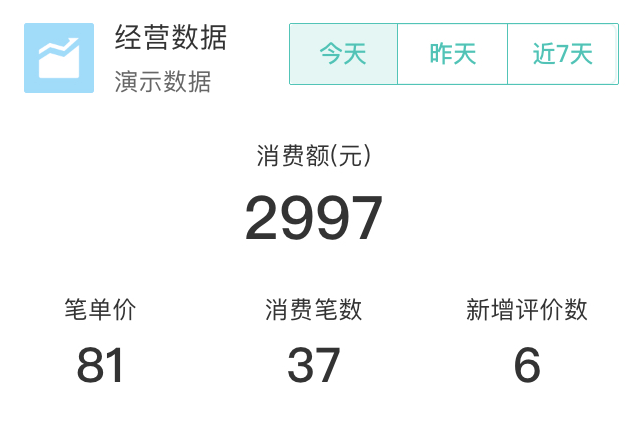
- 美团开店宝的实时经营数据卡片。
美团开店宝作为美团商家的客户端,支持着众多餐饮商家的辅助经营,而经营数据的实时性对影响商家决策尤为重要。该功能上线之后受到了商家的热烈欢迎。卡片展示如下图:
- 美团点评金融合作门店的实时热度标签。
该功能用于与美团点评金融合作商家增加支付标签,用以突出这些商家,增加营销点。另一方面为优质商家吸引更多流量,为平台带来更多收益。展示如下图:

总结与展望
以上就是该系统的设计框架与思路,并且部分功能已应用到系统中。为了商家更好的决策,用户更好的体验,在业务不断增长的情况下,对实时数据的分析就需要做到更全面。所以实时数据分析还有很多东西可以去做。
老生常谈的大数据 4V+1O 特征,即数据量大(Volume)、类型繁多(Variety)、价值密度低(Value)、速度快时效性高(Velocity)、数据在线(Online),相比离线数据系统,对实时数据的计算和应用挑战尤其艰巨。在技术框架演进层面,对流式数据进行高度抽象,简化开发流程;在应用端,我们后续希望在数据大屏、用户行为分析产品、营销效果跟踪等 DW/BI 产品进行持续应用,通过加快数据流转的速度,更好的发挥数据价值。
参考
- 多元线性回归模型
转自:https://tech.meituan.com/2018/01/26/realtime-data-measure.html