
最近在调试sparkStreaming程序的时候,遇到一个问题:
我设置的sparkStreaming的相关参数如下:
spark.executor.instances: 56
spark.executor.memory :2G
spark.driver.memory:5G
按照这部分参数,计算出来申请的内存大小应该是:
56 * 2G + 5G = 117G
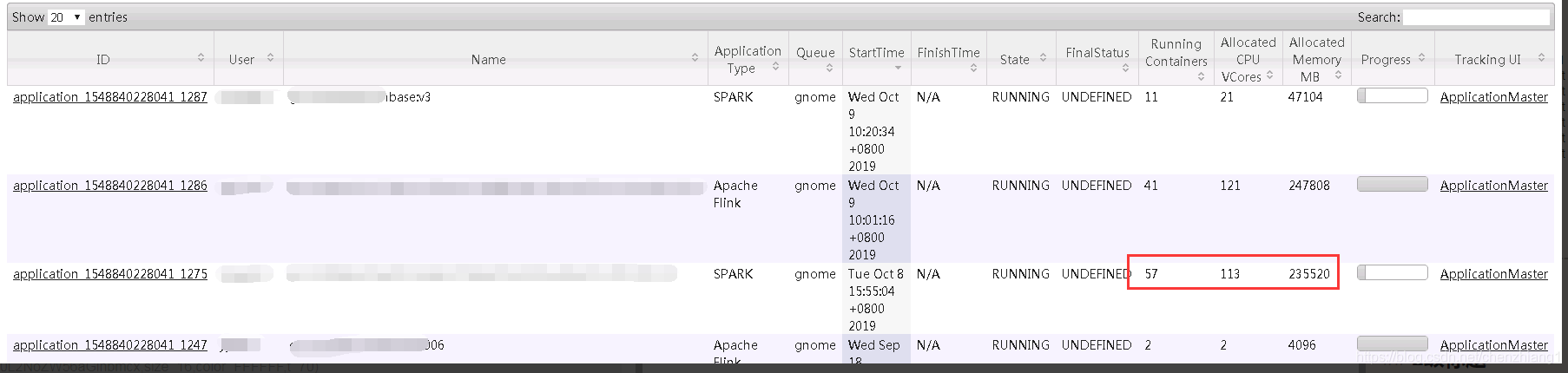
但是任务提交之后,从yarn的资源管理界面看到申请的内存大小为:
235520M = 230G
几乎是理论值的两倍
十分困惑这个值是怎么算出来的,经过一番调研,现将这个spark on yarn内存的计算方式进行梳理,如下:
一、yarn和spark的一些概念
1、spark任务会根据自己的executors的个数向yarn申请对应个数的container来跑任务,每个executor相当于一个JVM进程。
2、除了跑任务的container,yarn会额外给每一个spark任务分配一个container用来跑ApplicationMaster进程,整个进程用来调控spark任务。对于spark任务,ApplicationMaster内存大小由上面的spark.driver.memory控制
二、spark on yarn内存申请
1、yarn两个默认内存参数
yarn.scheduler.minimum-allocation-mb 每个container的最小内存值
yarn.scheduler.maximum-allocation-mb 每个container的最大内存值
也就是说,
a、如果你设置的spark.executor.memory参数值比yarn.scheduler.minimum-allocation-mb小,那yarn生成的container内存大小会默认会使用yarn.scheduler.minimum-allocation-mb的值。
b、如果你设置的spark.executor.memory参数值比yarn.scheduler.maximum-allocation-mb大,那yarn生成的container内存大小默认会使用yarn.scheduler.maximum-allocation-mb的值。
c、还有个隐藏的条件,yarn生成的container内存大小必须是yarn.scheduler.minimum-allocation-mb值的整数倍
2、spark
spark on yarn有一个memoryOverhead的概念,是为了防止内存溢出额外设置的一个值,可以用spark.yarn.executor.memoryOverhead参数手动设置,如果没有设置,默认memoryOverhead的大小由以下公式计算:
memoryOverhead = max(spark.executor.memory * 0.07,384)
// Executor memory in MB.
protected val executorMemory = args.executorMemory
// Additional memory overhead.
protected val memoryOverhead: Int = sparkConf.getInt(“spark.yarn.executor.memoryOverhead”,
math.max((MEMORY_OVERHEAD_FACTOR * executorMemory).toInt, MEMORY_OVERHEAD_MIN))
// Number of cores per executor.
protected val executorCores = args.executorCores
// Resource capability requested for each executors
private val resource = Resource.newInstance(executorMemory + memoryOverhead, executorCores)
3、yarn对spark任务内存的申请计算方式
现在我们看看上面的235520M = 230G是怎么计算出来的
前提:我们线上yarn的yarn.scheduler.minimum-allocation-mb设置的是2G
再把spark的参数列一下:
spark.executor.instances: 56
spark.executor.memory :2G
spark.driver.memory:5G
a、executer使用的内存计算
memoryOverhead = max(spark.executor.memory * 0.07,384)
= max(2 * 1024 * 0.07,384) = 384M
则一个executor实际要使用的内存大小为:
totalMemory = spark.executor.memory + memoryOverhead
= 2 * 1024 + 384 = 2432M
又因为yarn.scheduler.minimum-allocation-mb = 2G = 2048M
又由yarn的container内存大小的性质可知,container内存大小必须是yarn.scheduler.minimum-allocation-mb的整数倍,我们现在需要的内存大小是 2432M,而yarn.scheduler.minimum-allocation-mb是2048M,那么比2432M大且是2048M整数倍的最小值是4096M=4G,所以实际上yarn为spark申请的每个container的内存大小并不是我们设置的2G,而是4G
这样,我们有56个executor,也就是会申请56个container,则消耗的总内存是 56 * 4G = 224G
b、driver的内存计算
计算方式和上面一样:
memoryOverhead = max(spark.driver.memory * 0.07,384)
= max(5 * 1024 * 0.07,384) = 384M
则driver实际要使用的内存大小为:
totalMemory = spark.driver.memory + memoryOverhead
= 5 * 1024 + 384 = 5504M
同理,比5504M大且是2048M的整数倍的最小值是6144M=6G
故driver实际申请的内存大小是6G
所以整个spark任务最终申请的总内存大小为 224G + 6G = 230G
————————————————
版权声明:本文为CSDN博主「冰血_ang」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/chenzhiang1/article/details/102488609/