
- E:\Adaboost\
- ———positive\ //正样本文件夹
- ———pimages\ //正样本图片所在文件夹
- ———pos.dat //正样本集描述文件
- ———pos.vec //正样本特征集描述文件
- ———nagative\ //负样本文件夹
- ———pimages\ //负样本图片所在文件夹
- ———nag.dat //正样本集描述文件
正样本
1 收集样本
找617张带有车牌的图片,一开始设置大小 200*200 左右,报内存错误。
后来重做,即将617张图片中的车牌用画图软件截取下来,重新设置大小为60*17,并保存为bmp文件。
我这人比较懒,617张车牌的照片?其实还是不容易找的。我是这样做的:
1.1 先收集类似图片
运用 网页图片保存能手 这个软件批量下载图片(这个软件找的好辛苦,试过其它的有的收费有的基本不能用)
我在百度图片搜的关键词有 “车牌” “车牌号” “苏州车牌” “江苏车牌” 等等,获取了近7000张的图片
1.2 利用以前写的小软件截取车牌
运用自己以前写的小程序:车牌图片截取软件(运用opencv基于纹理检测车牌,由于效果不太好,姑且用来为adboost提供辅助收集车牌图片),
设置好样本图片所在的输入路径,在设置好车牌输出路径,运行即可得到 60*17 大小的bmp图片
下载地址: http://download.csdn.net/detail/mkr127/5374301
PS由于效果不怎么好吗,所以在出来的图片中你得删掉无用的图片,于是,几千张的图片我只收集到了617张车牌图片,哈哈,很麻烦的。
BUG这个小软件有bug,我懒得改,即图片太大如5400*2700有时会出错,还有每次运行的图片不要太多,不然会出错,将图片 2000张一组就没有问题。
当然,如果你不喜欢,可以自己手动截取。
1.3 将得到的617张正样本图片放在E:\Adaboost\positive\pimages\文件夹中
1.4 负样本图片
即不包含车牌的图片,我收集了几千张,用matlab 批量格式化为 200*200大小的bmp图片,放在E:\Adaboost\nagative\pimages\文件夹内
2
创建正负样本描述文件
2.1 正样本描述文件
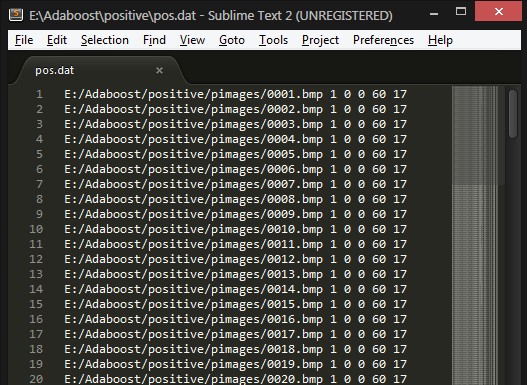
cd E:\Adaboost\positive
dir pimages /b > pos.dat
运用文本编辑软件对生成的文件 pos.dat 进行替换修改:
a: 将jpg 替换为 jpg 1 0 0 60 17
b: 选择所有,tab键,将tab 替换为图片所在路径
得:
2.1 负样本描述文件
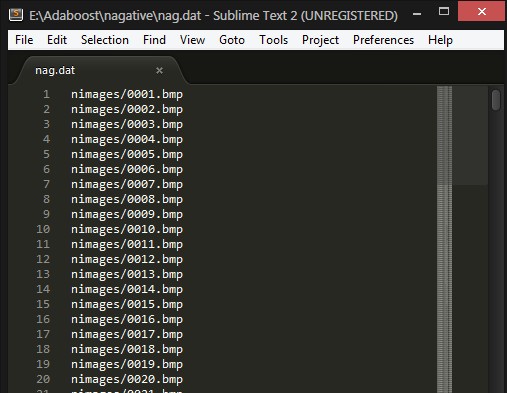
cd E:\Adaboost\nagative
dir pimages /b > nag.dat
运用文本编辑软件对生成的文件 pos.dat 进行替换修改:
选择所有,tab键,将tab 替换为图片所在路径
得
3 设置环境变量
添加Opencv库中opencv_createsamples的环境变量,以便于在cmd中执行,在path中最后添加 ;C:\OpenCV\opencv\install\bin
4 创建正样本特征集描述文件
打开cmd,进入positive所在文件夹
cd E:\Adaboost\positive
opencv_createsamples -vec pos.vec -info pos.dat -num 617 -w 60 -h 17
//-num 正样本数量 -w图像宽 -h高
如下图所示
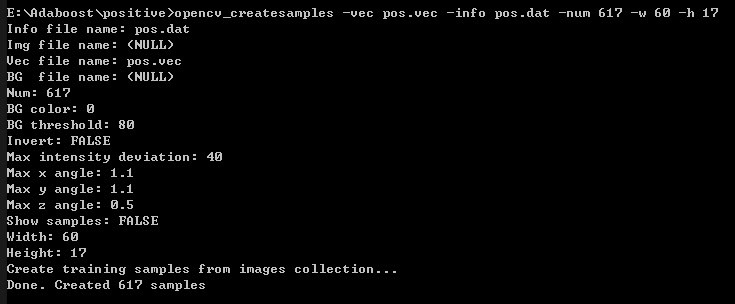
在E:\Adaboost\positive下生成pos.vec文件,即正样本特征集描述文件。
5 开始训练
cd E:\Adaboost\nagative
opencv_haartraining -data trainout -vec e:\Adaboost\positive\pos.vec -bg nag.dat -npos 317 -nneg 300 -mem 40000 -mode ALL -w 60 -h 17
//-mem分配的内存大小 -w正样本宽 -h正样本高
//-npos正样本数量,-nneg 负样本数量,至于为什么是这个值,最后将有分析。
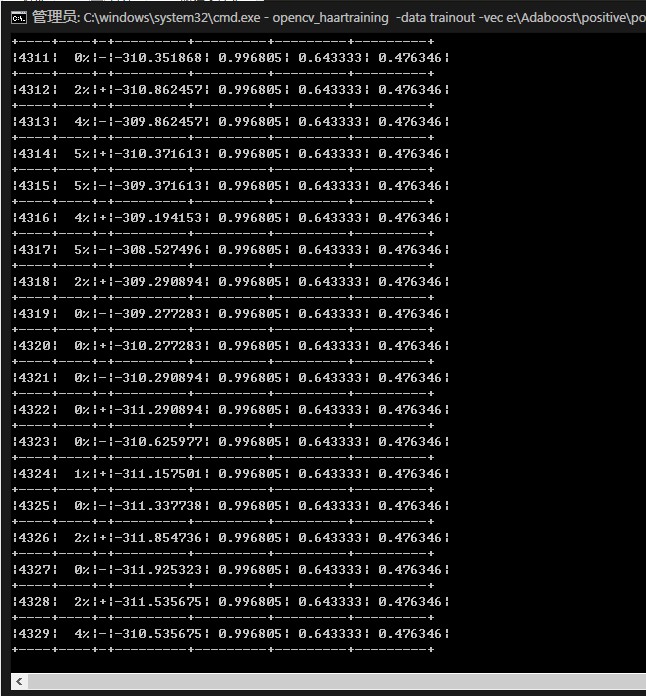
6 遇到的错误
6.1 内存不够的错误
那是因为正样本图片太大了,我改为60*17就正常了
6.2 OpenCV Error: Assertion failed (elements_read == 1)
原因:-nneg -npos 参数出错
参考:
http://bbs.csdn.net/topics/390388465
http://askbot.alekcac.webfactional.com/question/3085/why-always-opencv-error-assertion-failed-elements_read-1-in-unknown-function/
我英文不太好 – -!初步分析认为:
假如我有正样本总数 617 ,npos(正样本参数设置的大小,待定);负样本数 nneg 待定(我原有3000张左右), nstages 12
617 >= npos + (12-1)*0.001*npos +nneg
那么假如分配 nneg=300,则
npos<= (617-300)/1.011 = 317
6.3 再次测试
- opencv_haartraining -data trainout -vec e:\Adaboost\positive\pos.vec -bg nag.dat -npos 317 -nneg 300 -mem 40000 -mode ALL -w 60 -h 17
问题搞定,我没有设置-nstages=12 也没错,额,待进一步研究。
结果
跑到第四层的时候,跑了一天两夜,仍然是第4阶!哥不淡定了,查查估计是死循环了,网上说适当增加负样本,
那么我在控制台中 Ctrl + C, 注意,是可以断开的,以前我一直不敢…原来在执行训练的话会自动加载 以前训练的级,估计这就是级联吧,都是自己摸索的,纯粹的供大家参考,有不到之处尽请谅解。
我将负样本增至600
- opencv_haartraining -data trainout -vec e:\Adaboost\positive\pos.vec -bg nag.dat -npos 317 -nneg 600-mem 40000 -mode ALL -w 60 -h 17
这时候在很短的时间内跑到了第10阶。进一步探究中。
接上
请注意,要确保 nag.dat 里面的数据大于600行,因为上一步执行到第10层时停止不动了
就停在这里,于是我找到 nag.dat(负样本描述文件)发现里面的数据只有300行,怪不得,于是我追加打到1269行,此时我再执行
E:\Adaboost\nagative>opencv_haartraining -data trainout -vec e:\Adaboost\positive\pos.vec -bg nag.dat -npos 317 -nneg 900 -mem 40000 -mode ALL -w 60 -h 17
继续向下训练
截图为证
报一下我的数据,pos.dat =617行, pimages =617张 , nag.dat= 1269行 , nimages= 1269张
trainout 训练到第十层
继续向下探索,由于我对着个完全没有经验,如果大家觉得太过幼稚简单,可以移步,呵呵,纯当给像我这样的一无所知之人一个借鉴。
仅此而已。
训练结束
得到 分类器:
这时我在增大负样本数到1269 发现到13级就训练结束了,和负样本数为900的没有区别,并且 E:\Adaboost\nagative\trainout.xml 自动更新覆盖为最新版,这下我就不用担心以前的成果白费了,当然,最好做个备份,E:\Adaboost\nagative\trainout 这里面的数据不要删,以后增加正负样本的数量的话我估计会自动累加,呵呵。
接下来开始测试:利用之前写的人脸检测代码,将分类器改成我们测试的分类器,一切就容易起来!
实验的结果还是挺差的,估计是样本太少了,我的正样本才600多,专业的最少都7-8000,也有可能是我的正样本图截的不好,用软件截的,没有手工的准确,再者就是网上的图片不行,真正好的样本还是比较少的。
测试结果:
接下来就是增加样本数量,最后还不好的话,就增大样本质量,哈哈!
如果以后有经历,就写个MFC通用的提取分类器的小程序,用来测试分类器的性能。
本人写的通用小项目下载地址:可以提取分类器进行检测,大家必须配置好OpenCV环境和在源码中设置好分类器的路径。
http://download.csdn.net/detail/mkr127/5397219
项目用到的正样本训练库,额,分有点高,毕竟是本人从几千张图片中一张一张筛选出来的…算是我的辛苦费吧,勿喷我……
http://download.csdn.net/detail/mkr127/5418861
60-17像素bmp车牌 共617张。
转自:https://www.cnblogs.com/young525/p/5873831.html