码字不易,转载请注明出处!
前面我们制作好了训练所需要的文件:train.rec,property,以及验证时所需要的val.bin,那么接下来就是该探索如何进行数据的训练。
这部分内容相对来说比较简单,毕竟框架和代码都是作者已经写好的,可供更改的内容还是有限的,所以也没有太多技巧的内容,更多就是按部就班的来。
模型训练
训练文件在”src”=>”train_softmax.py”文件内:
打开train_softmax.py文件后,主要关注的是一些训练参数,这里的内容还是挺多的,需要花点时间看下每项都在做什么。
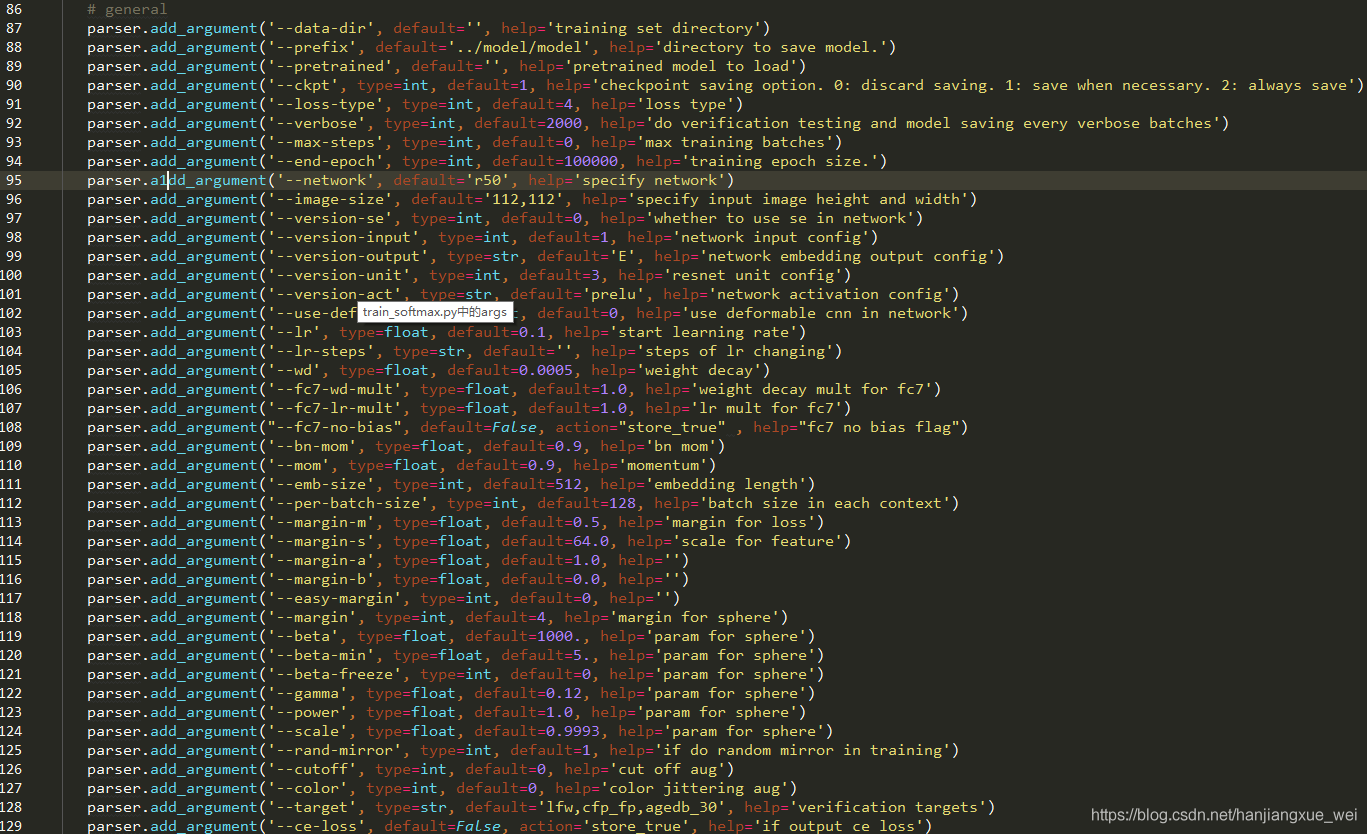
我们用到的内容主要有以下几个:
87行中,我们需要指定我们制作的训练样本train.rec文件所在的文件夹
88行中,我们需要指定将来模型训练好之后保存到哪个位置
89行中,表示我们所使用的作者提供的预训练模型路径和名称
91行中,表示我们所希望使用的loss种类,这里作者提供了5中loss可供使用,分别是1)原始的softmax、2)SphereFace;3)cosineface;4)arcface;5)各种loss结合版本。这部分内容在作者的github主页上面有介绍:

5. 92行中,表示每隔多少个iteration做一次验证并保存模型
6. 95行中,network表示使用何种网络模型,在路径”src”=>”symbols”文件夹下有不同的模型,并且在代码中也用get_symbol()函数中定义了不同的模型,可以根据自己的需求使用,这里作者默认为resnet50
7. 97行中,是否使用se网路结构,这部分内容可以查看Squeeze and excitations networks论文,作者在论文中是使用的,模型的表现也不错,虽然默认是0,但是建议还是用上。
8. 112行中,设置batchsize的大小
9. 113-114行设置特征归一化后的大小和margin的大小,这部分内容很多论文都有提到
10. 128行中,target表示验证数据。作者原始使用了lfw、cfp、agedb三种验证集,但是我们这里因为要使用我们自己的,所以这里可以通过参数更改,或者直接在默认值中添加我们的数据集。并且,一定要注意的是,这里的target一定得有,不然网络训练中是不会保存模型的。即使我们在92行中设定了验证的间隔,但是如果我们没有提供验证数据,就不会有验证的过程,而且也不会保存模型。我在刚刚开始训练的时候,没有添加验证集,结果导致了模型训练了好久,训练准确度虽然提升了,但是由于没有验证集,所以模型不做验证也不保存数据。所以这里一定要加上。
别的内容自己了解下,根据自己的需要进行下尝试。
实际在使用的时候,依然是将训练参数写入一个.sh文件中,这样就可以直接通过更改.sh文件的内容来达到控制网络运行的目的:
#!/usr/bin/env bash
CUDA_VISIBLE_DEVICES=’0′ python -u train_softmax_my.py –prefix ../models/model-r50-am-lfw –loss-type 0 –data-dir ../dataset/train –per-batch-size 32 \
–version-se 1 –verbose 1000 –target val –margin-s 64 –emb-size 512
上面的参数可以解释为,使用0号gpu,训练我的train_softmax_my.py文件,预训练模型保存路径为上级目录中的models文件夹内的”model-r50-am-lfw” ,使用原始的softmax损失,数据存放路径为上级目录中的dataset文件夹中的train文件夹内,batchsize为32, 使用se网络,每隔1000次进行一下验证,并保存模型,验证集的名称为val,因为它与train文件是放在同一个目录下的,所以模型自己会去train的路径下去找,归一化后特征尺度为64,最后的输出特征层的维度为512维。
那么在命令行敲入sh 你的sh文件名称.sh或者 ./你的sh文件名称.sh文件就可以跑起来了。
模型验证
同样是在”src”=>”train_softmax.py”文件中的第403行:

我们可以看到,定义了一个ver_test()函数来进行验证,验证使用的是verification.test函数,这部分的内容是在”src”=>“eval”=>”verification.py”文件中定义的。
而调用ver_test()函数,则是通过系统的一个回调函数来进行调用:
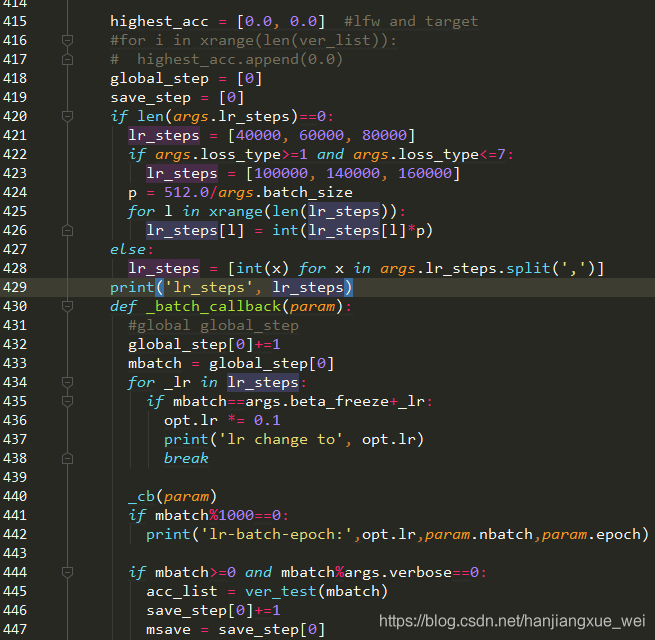
从上图中可以看到,418行中初始化了一个global_step,训练的时候会在432行中将这个变量加1,并将值赋给mbatch变量,当这个mbatch变量满足444行中的判定条件,那么就调用ver_test函数,从而进入验证阶段。
而验证阶段的目的只有一个:采用n-fold交叉验证的方式,确定一个阈值来使模型对验证集中相同的图相对判定为1,不相同的图相对判定为0。
具体而言,在”verification.py”文件中,找到test函数:
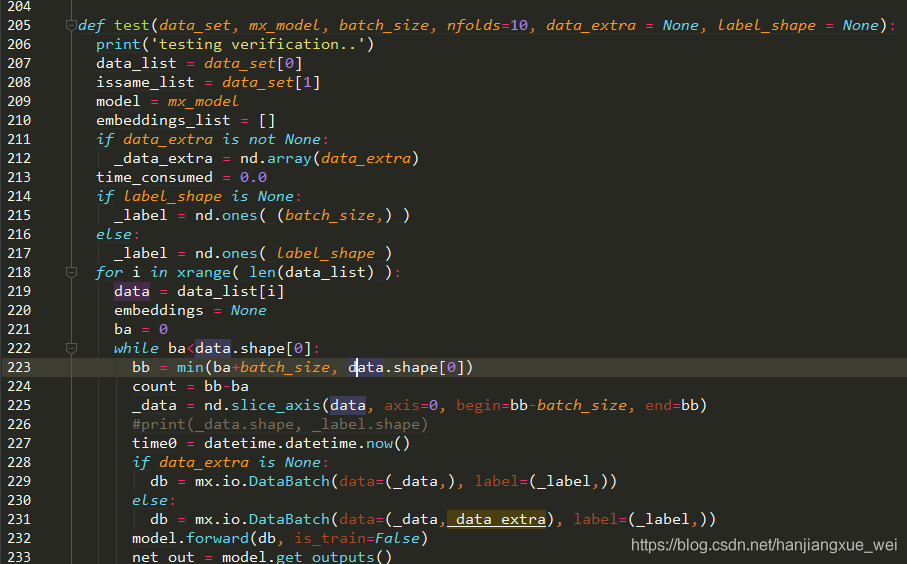
可以看到,该函数加载了数据和模型之后,通过将训练数据data_set划分为多个batch之后,得到_data,然后将其送入网络中进行前向推理(232行),获得输出的特征。也就是通过这部分内容,net_out变量保存的内容就是网络在前向推理得到的不同图像的特征向量。
然后对特征向量进行后续的操作:
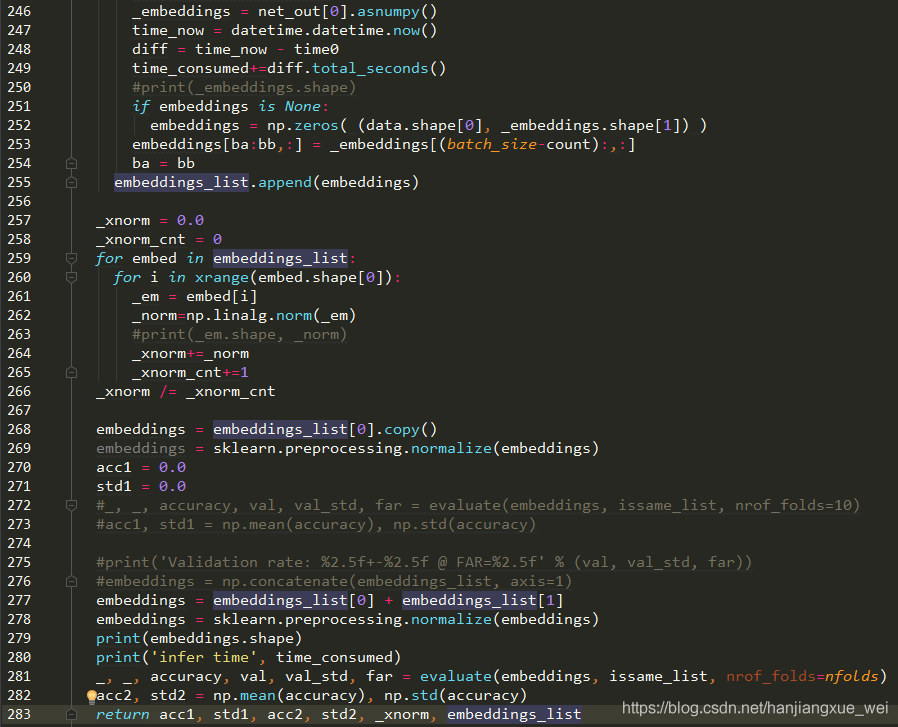
从上图中可以看到,这里首先对特征向量进行了标准化(278行),然后将标准化后的特征向量送入281行中的evaluate函数进行评估。而evaluate函数如下:
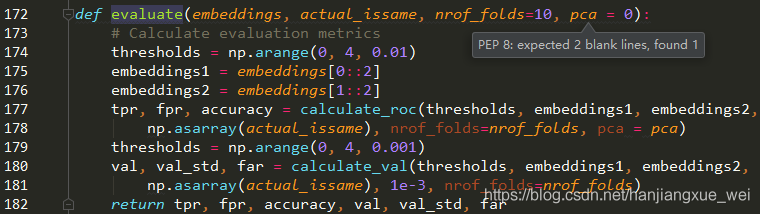
可以看到,这里设定的阈值为从0到4,变化幅度为0.01,一共400个阈值,算法将从这400个阈值中选取最合适的阈值。注意,这个函数输入的参数embeddings其实在上一步中已经对输入的图相对进行了重新组合,还是拿上面的NBA例子作为示例,原来我们送入的图像对是这样的:
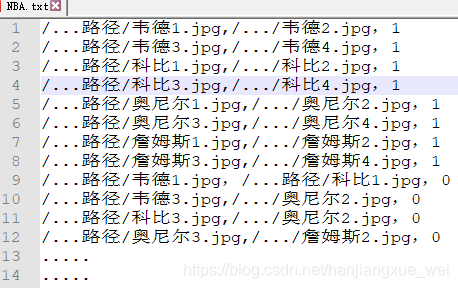
但是这里已经embeddings中保存的图像为如下形式:
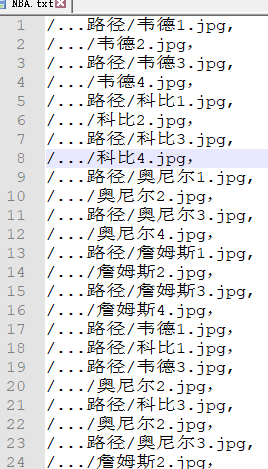
唯一的区别就是,这里的embeddings分别对应着每个人的特征向量,而不是原始图像。embeddings1和embeddings2分别保存着embeddings中特征向量的奇数行和偶数行,这样做可以非常方便的进行比较操作,比如embeddings1[0] (韦德1)和embeddings2[0](韦德2)就表示相同,actual_issame[0]对应为1,embeddings1[3](科比3)和embeddings2[3](科比4)也表示相同, actual_issame[1]为1,但是embeddings1[8](韦德1) 和embeddings2[8](科比2)就表示不相同,actual_issame[8]为0。当然也可以不这样做,只不过操作稍微麻烦一点。
在177行,所有的内容都被送入calculate_roc中进行计算,求取tpr和fpr。
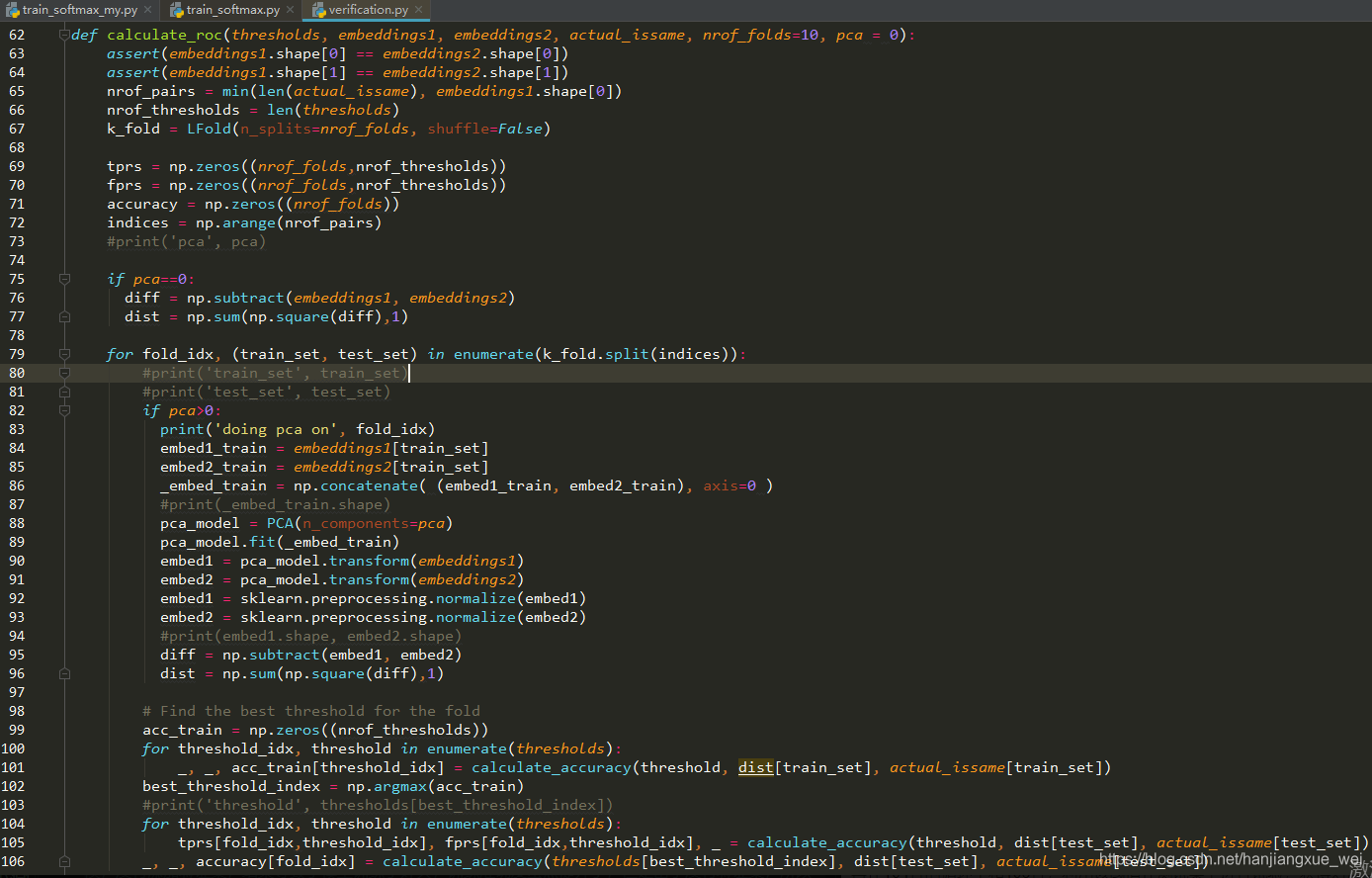
该函数中,首先根据参数将送入的embeddings和标签actual_issame划分为k-fold(这里为10折),然后对两个特征向量求取欧氏距离(76、77行),以便下步计算两者之间的相似度。
而且,在79行,将特征向量划分为训练集和验证集(划分比例为9:1),然后在100行的循环中将训练集送入calculate_accuracy函数中,计算训练集在不同阈值情况下的准确率。得到最高的准确率所对应的阈值之后,再在104行的循环中和106行,利用该阈值在测试集上进行试验,获得对应的准确率指标。这样总共经过10次循环,就可以计算出在10次划分中,不同划分下的最优阈值,这个阈值将是我们将不同人脸区分开的重要阈值。
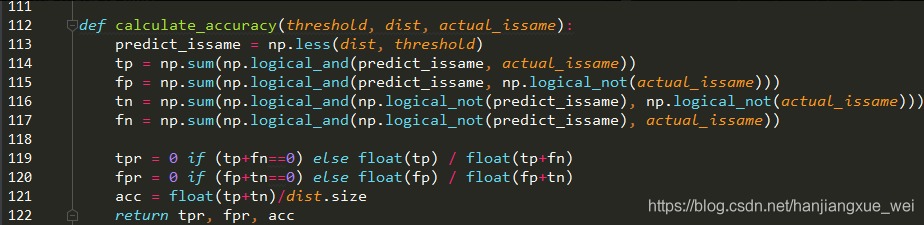
这里,我们可以看到,函数是对不同阈值情况下的不同划分,计算器混淆矩阵,然后求解tpr和fpr和acc。这里假设我们将相同人的图像对认为是正样本,不同人的图像对认为是负样本。
tpr表示的就是:所有的正样本中,模型正确判断其为正样本所占的比例。
fpr表示的就是:所有的负样本中,模型误判某些负样本为正样本所占的比例。
acc表示的就是:所有样本中,正样本和负样本都划分对的部分占所有样本的比例。
因为对于不同图像对来讲,我们的希望模型能够尽量把相同的人和不同的人都划分正确。但实际上是不可能的。通常我们希望tpr越高越好,代表模型能够充分将正样本判定为正样本;同时,也希望模型fpr越低越好,表示模型不会对负样本发生误判。而实际上这两者之间是互相制约的。想要tpr高,则模型应该不要太敏感,但是如果模型不敏感,那么fpr就会升高,反之亦然。所以实际上在使用中是根据需要尽量取到一个平衡点。
总之,通过了10折交叉验证,我们获得了在不同的阈值情况下的一个准确率。而使得准确率最高的阈值就是我们想要的。
通过上面的过程,就完成了模型的验证过程。并且得到了不同人脸之间区分的阈值,那么这个阈值就是我们将来进行人脸识别重要指标。如果两个人的特征向量之间的距离小于该阈值,那么我们判定其为同一个人,如果大于该阈值,则判定其为不同的人。
通过训练和验证过程,我们最终获得了一个训练好的模型和一个计算好的阈值。其实到这步我们就已经具备了1:1的识别能力了。但是想要实现1:N,我们还需要构建一个人脸特征库。这部分内容在下节进行介绍。
————————————————
版权声明:本文为CSDN博主「hanjiangxue_wei」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/hanjiangxue_wei/article/details/86566435