
码字不易,转载请注明出处!
有了前面的准备工作之后,我们就开始动手了。
Let The Hunt Begin!
数据集规模
数据当然是越多越好,然而实际我们可能没有那么多数据,那么多大的量就可以了呢?吴恩达的教程里面说过,怎么着也得有个几千到几万张吧。因为我们不是从头开始训练,有了预训练模型的话,可以很大程度上减少对于数据的需求,这当然对于实际使用显然不够,但是对于学习项目而言,差不多了。
打个比方,假设要做一个NBA球星的识别,球星有“詹姆斯”、“韦德”、“科比”、“奥尼尔”。总共四个类别,和传统的分类不一样的地方在于,这里我们只关注脸,因为人脸识别需要最小化类内距离,最大化类间距离,那么也就意味着,所收集的图像要尽可能包含这四个人人脸在不同条件下如角度、光照、表情等不同的图像,而且每种条件下的图像最好能有多张。这样算下来,每个人也得有几百张,合起来也有个几千张,越多越好。
这部分数据需要自己耐心点,人工去筛除不满足条件的或者质量差的,保证数据集的干净。
数据集划分
因为我们最终的目的是想要实现1:1或者1:N,那么我们还需要从已有的数据集划分出来一些用做验证,将来来选取不同人之间的阈值。所以我们需要从自己筛选好的图像中,选出一部分作为验证集。验证集也需要尽量保证同一个人在不同条件下的图像,而且不能与训练集重复。比如每个人选取10张图像出来。
数据增强
如果实在没那么多数据,那么可以进行一下数据增强。这里可以采用对比度增强/减弱、亮度增强/减弱、水平翻转等。但是如果采用旋转变换,那么建议一定不要做太多的幅度,因为后面要用mtcnn进行人脸检测和校正,如果旋转太大,那么非常容易造成人脸检测效果下降。
人脸检测与校正
这部分内容作者是直接使用mtcnn做的,当然作者也提供了ssh的代码,可以根据需要选择使用。mtcnn的主要好处就在于不仅能够检测人脸,而且能够检测人脸的关键点,并利用这些关键点进行图像校正,从而在一个前向完成了两个任务,这点比ssh要好点。但ssh能检测更小的脸,各有优势吧。
这部分的代码在”deploy”=>”test.py”中:
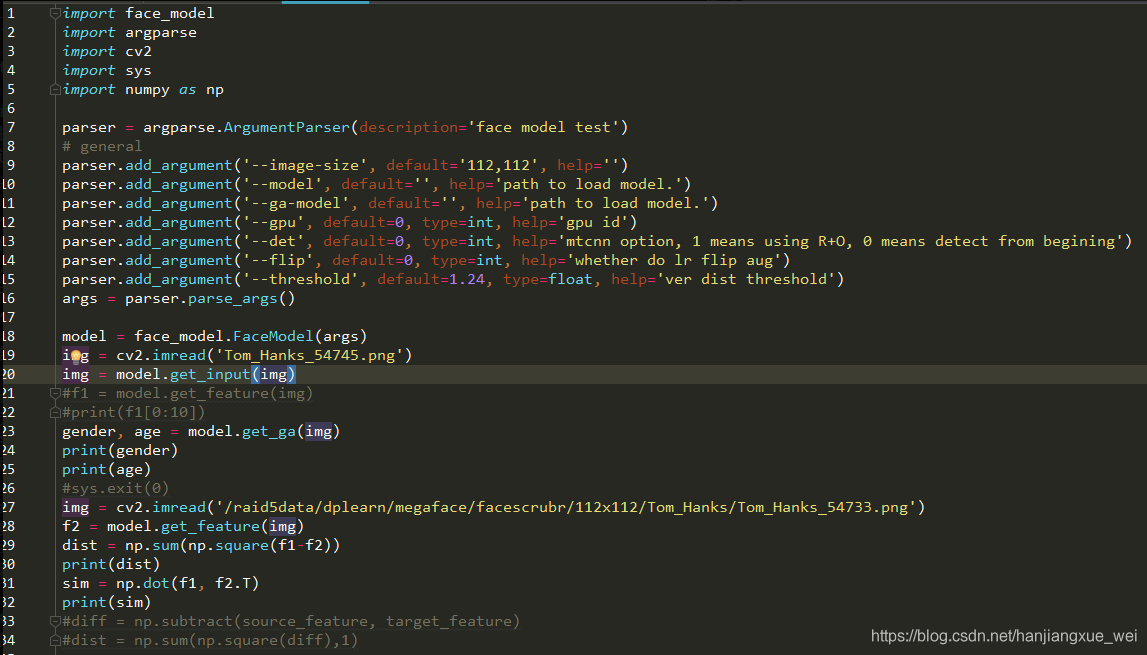
这里其实我们可以看到,作者的示例中,在19行,通过model.get_input()函数产生了一个img,这个img其实就是我们要的人脸检测并校正之后的结果。通过9行参数,我们知道,产生的人脸图像大小是112 × \times× 112大小的。所以我们可以根据自己的需求,传入不同的参数或者更改一下默认的参数,来方便对我们自己的图像进行检测,然后产生我们自己的人脸检测结果。
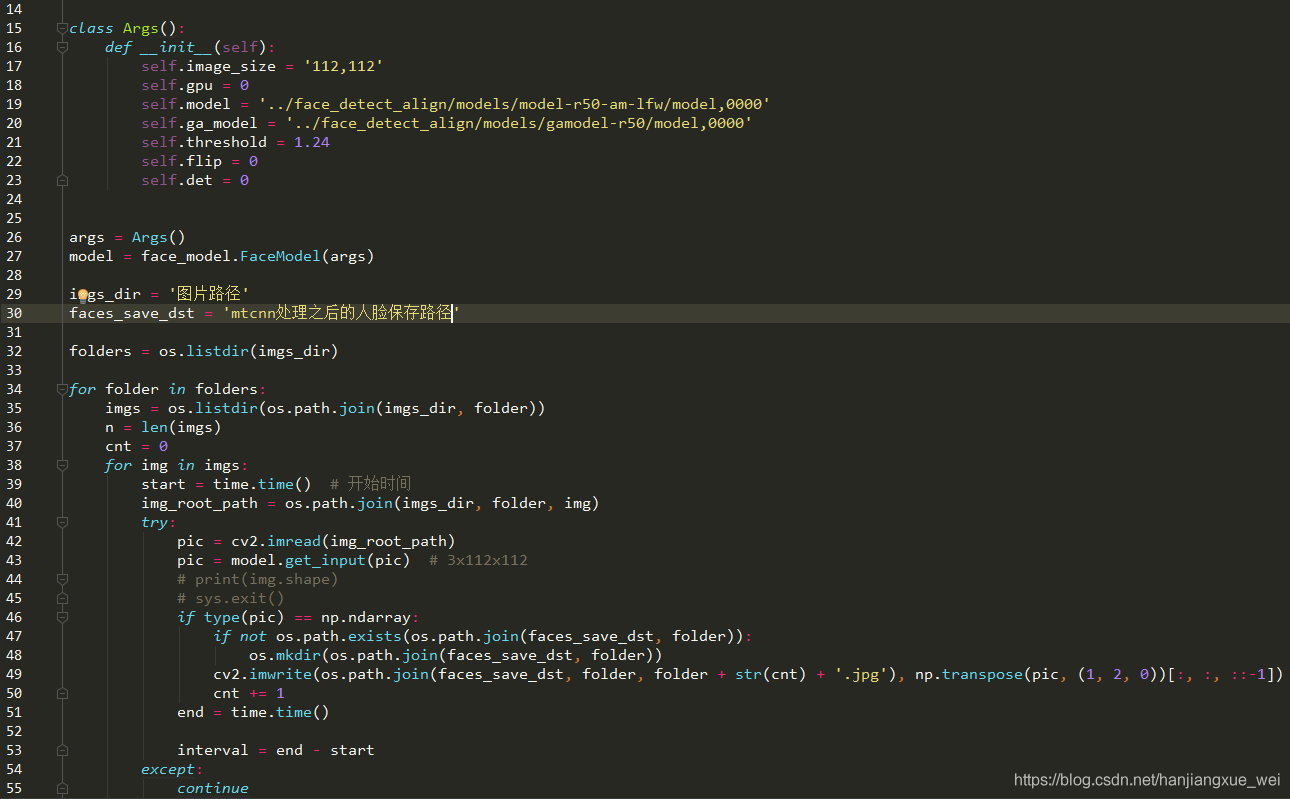
经过以上的过程,我们就可以在我们的目标文件夹内得到我们的人脸图像,可以发现,人脸检测之后对检测结果进行了边缘扩充,从而保证人的发型、整个头部都包含在图像中。

后面就开始制作训练集和测试集了,而这部分内容的操作对象都是我们刚刚保存好的人脸图像文件夹,所以不要弄混了。
训练数据.rec的制作
MXNet训练时的标准输入文件是.rec形式的,就类似于tensorflow中的.tfrecord形式。所以我们需要做一个.rec文件,而制作文件在”src”=>“data”=>”face2rec2.py”里面。 ,这里我用的是https://github.com/apache/incubator-mxnet/blob/master/tools/im2rec.py代码,没有使用原始的代码,所以可能会在运行上面代码的时候出错。后面将face2rec2.py文件用上面链接中的代码替换即可,正常使用时的参数都是一样的,所以下面运行的时候,将”python face2rec.py”修改成”python im2rec.py”就好了。
而想要制作.rec文件,首先需要制作一个.lst文件,这个文件包含了所有图像的路径、标签、以及打乱之后的结果。只有制作好了.lst之后,程序才会根据.lst中对应的路径下找到文件,并对图像进行编码,存入相应的信息,最后才能制作成.rec文件。
对于上面的NBA的例子,我们只需要在一个文件夹比如说“NBA”文件下分开存放好我们四个球星的文件夹即可,比如:
那么应该做什么呢?
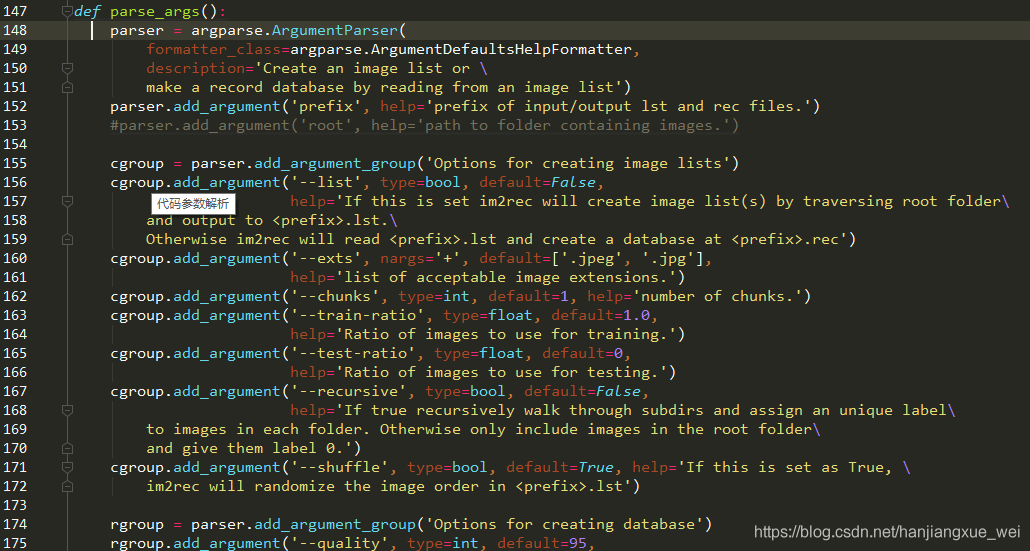
在156行说,如果想要制作.lst文件,那么我们需要在运行该代码的时候,加入–list 命令表明我们想要做.lst。然后在第167行,有一个 –recursive 命令,这个参数表明,如果你的文件夹下有多个类别,那么需要加入该命令来对文件夹下的所有文件进行搜索,对于我们的例子,需要加入这个命令。其他的命令可以自己看下,比如你有.png图像,那么可以将160行的default中加入’.png’。
实际运行的时候,是这样使用的:
python face2rec2.py –list –recursive /准备存放.lst的路径/准备存放.lst文件的名称(NBA) /图像文件夹路径/ 其他需要的参数
1
上面的运行代码用下面这个代码代替:
python im2rec.py –list –recursive /准备存放.lst的路径/准备存放.lst文件的名称(NBA) /图像文件夹路径/ 其他需要的参数
1
上面的.lst名称不要加后缀,只需要给出名称就可以了。
在运行完上面代码之后,程序会在你设定的路径下出现一个.lst文件,其内容是这样的:

第一列表示index,索引,第二列是label,第三列是图像路径。
那么下一步就是生成.rec了,这步其实和上面生成.lst文件的方式类似,还是运行上面的代码,只不过这回参数有点变化
python face2rec2.py /刚刚生成的.lst文件路径/.lst的文件名 /图像文件夹路径/
上面的代码用下面的代码替换:
python im2rec2.py /刚刚生成的.lst文件路径/.lst的文件名 /图像文件夹路径/
运行完上面的代码之后,会在你的当前路径下生成.rec文件,名称和.lst一样,后缀不一样。这部分内容没法查看,只能运行时加载后查看。

同时也会生成一个.idx文件,其实就是索引和label之间的对应关系,没什么用,可以忽略。
验证数据.bin的制作
验证数据主要用来寻找不同人之间的阈值划分,这部分内容不清楚的可以查看FaceNet那篇论文,只不过它用的方法是度量学习,与本文还不太一样。
而制作.bin文件需要预先制作一个人物名单对应表,比如存放于NBA.txt文件中,其内容是这样的:
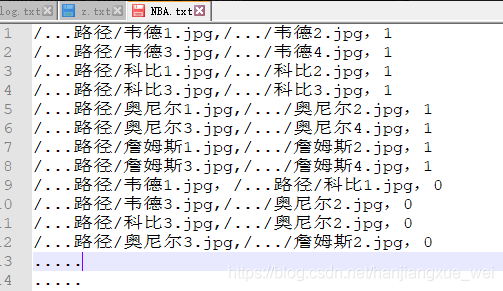
名单包含两种内容:
同一个人的两两组合图相对,标签是1,代表是同一个人
不同人的两两组合图像对,标签是0,代表是不同人
因为我们将来验证的时候,是需要模型能够区分是否是同一个人的,也就是说对于相同的人,它应该判定为1,不同的人,判定为0;这样我们才认为模型学会了区分不同的人。所以我们需要将这两种情况都制作在一个.txt文件中,前半部分全部是相同人的图像对,标签为1;后半部分是不同人的图像对,标签为0。
而制作名单可以有不同的方式,比如我们事先每个人都划分了10张图像进行验证,那么对于每个人,其可以进行排列组合,产生N(N-1)/2=45个不同的图相对组合;但对于不同人而言,怎么组合都可以,所以这部分可以根据自己的理解,采用一定的策略组合不同的人,比如最简单的就是将所有人的图像都放在一个列表里面,然后随机,取不同的名单。
好了,到此,我们准备好了.txt的人名名单(generate_image_pairs.py),那么我们应该能做.bin文件了。
这部分的代码在”src”=>“data”=>”lfw2pack.py”文件中。
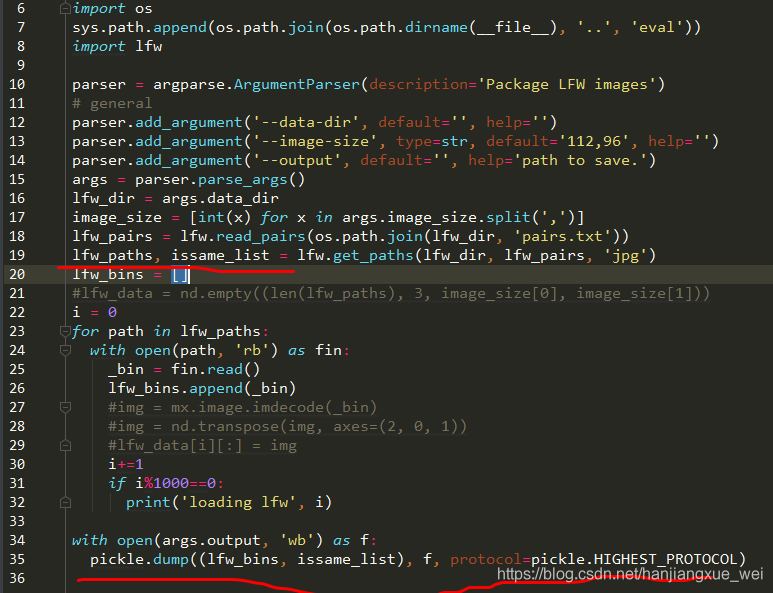
18行应该换成你刚刚做好的.txt文件,比如NBA.txt。
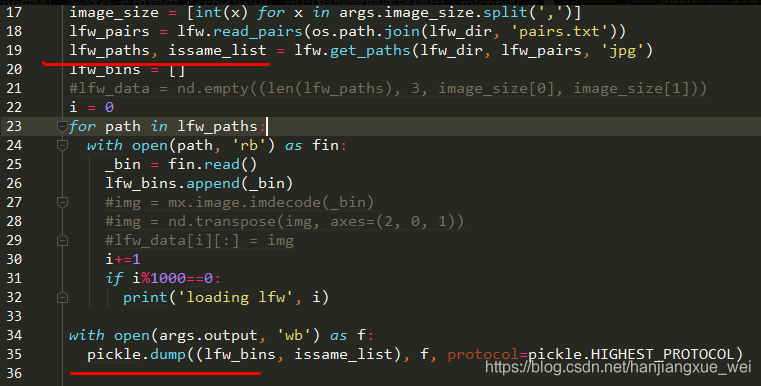
可以看到,关键的部分其实是在”src”=>“eval”=>”lfw.py”文件中,也就是18、19行这两个函数内。
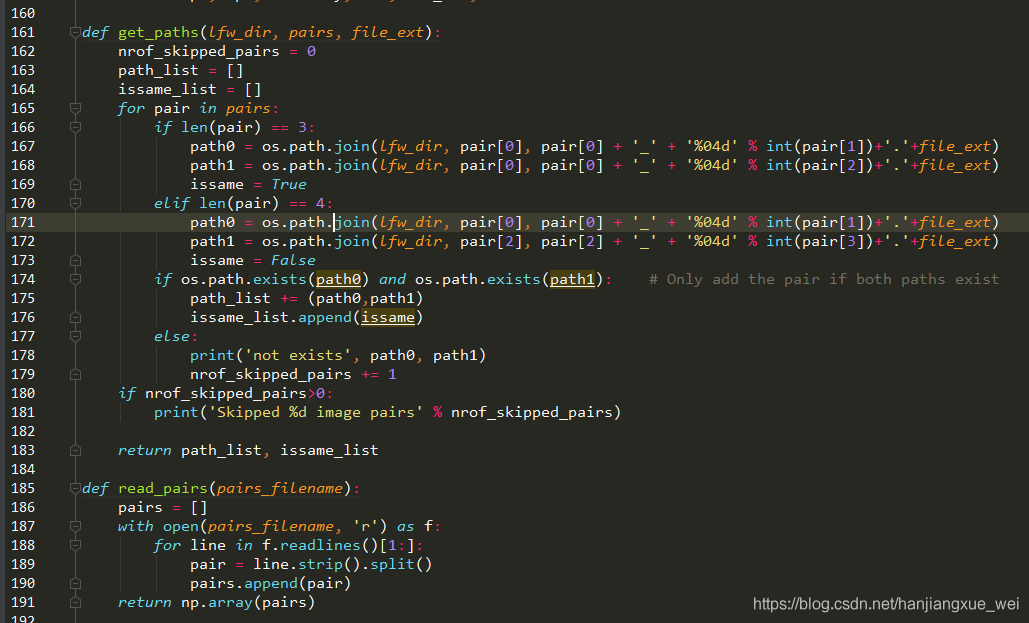
可以看到,185行的函数是将文件内容转化成了numpy形式,然后将结果传入161行的get_paths函数内,但是这个函数是原始按照LFW的制作方式来制作.bin文件的,我们的图像对形式与LFW的图像对形式是不一样的,这点可以到网上查看下LFW数据的图像对是什么形式的就知道了。我们这里不能采用这个做法,所以需要对这个函数进行改写。
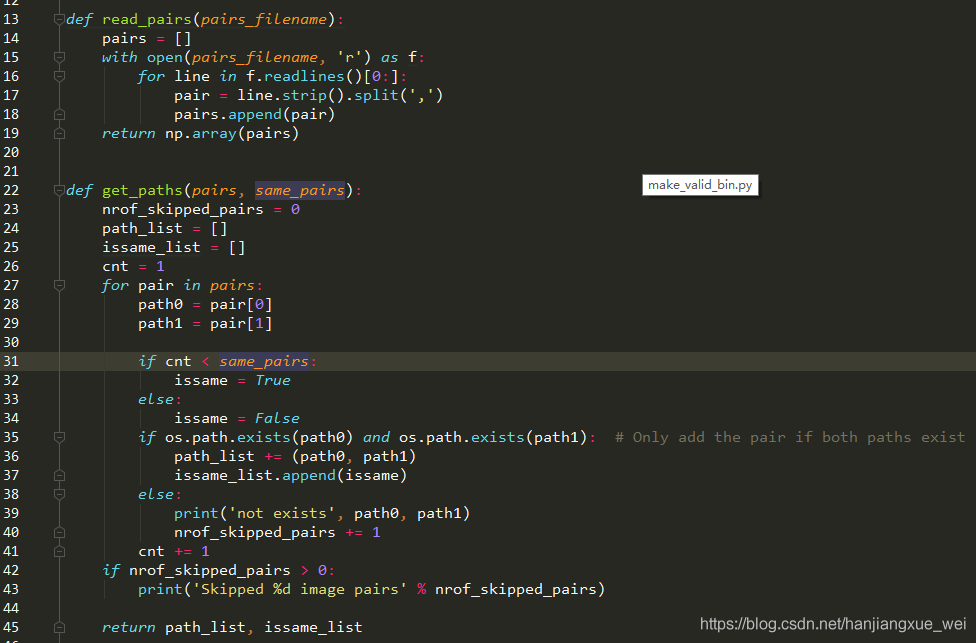
上面是我改写之后的,我们将函数传入参数改成了符合自己图像对的形式。其中的same_pairs参数表示我们之前做的图像对中相同人的对数。
当函数返回之后,我们产生了一个path_list 和 issame_list。然后在后面进行文件的制作,可以看到,文件是利用pickle进行了序列化,成为了一个二进制文件。

还有最后一个事情,就是我们在将来训练的时候,需要加入property文件,这个文件内主要包含我们图片的属性说明,可以自己新建一个空白文件,不要加后缀名,直接命名为property,然后打开之后写入我们的训练数据信息。
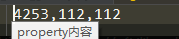
上面就是指我们有4253个id,每个id人脸图像的大小是112 × \times× 112大小
到此为止,我们的数据集就制作完了,那么下一步就开始进行训练了。
————————————————
版权声明:本文为CSDN博主「hanjiangxue_wei」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/hanjiangxue_wei/article/details/86566348