码字不易,转载请注明出处!
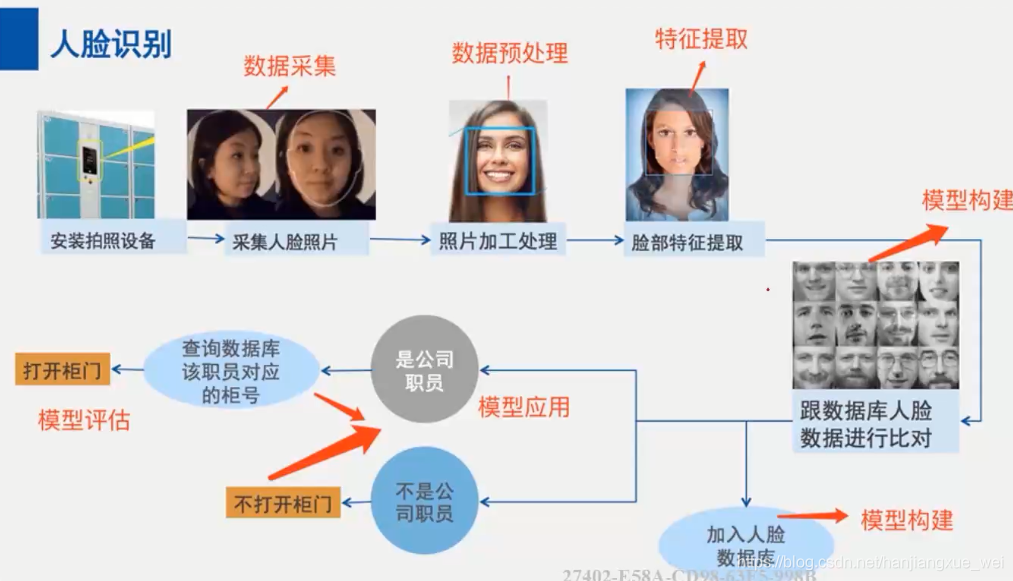
通过前面的几个小节,我们已经实现了模型的训练以及阈值的选取。此时利用我们已经训练好的模型和手上的阈值,我们已经能够做到1:1这样的验证了。所要做的就是拿两张图片,相同人或者不同人,然后送入网络中,网络会提取出来两个人的512维特征向量作为表征。然后计算两个向量之间的欧氏距离,如果该欧氏距离大于阈值,则判定为不同人;如果小于阈值,那么判定为同一个人。
但是要做到人脸识别,我们还需要最后一步:构建人脸特征库。
人脸特征库怎么建
这部分内容在arcface源码中并没有提供,但是在FaceNet的开源代码中(https://github.com/davidsandberg/facenet) ,在”contributed”文件夹中提供了一定的思路。

在real_time_face_recognition文件中,作者判定某人是不是在库里的过程如下:
首先在60行生成一个人脸识别器,然后从camera读入一个图片,然后在72行进行识别。
所以源头是face.Recognition()这个人脸识别器。通过查看face.py代码,我们可以看到:

这里的Recognition类中,使用Detection()、Encoder()、Identifier()三个类分别实例化了人脸检测器,编码器和识别器。
在该文件中给出了上面三个函数的实现,人脸检测器使用的是mtcnn进行人脸检测,返回的是当前图像中的人脸经过校准之后的bbox,编码器中,是对bbox中框出的人脸进行前向推测,获得了人脸的特征表示。然后将特征送入Identifier中:
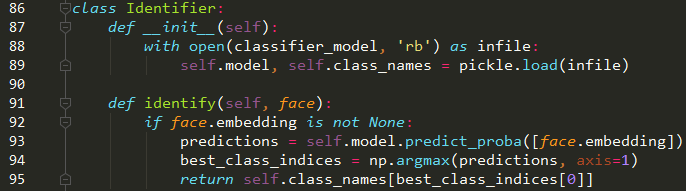
可以看到,identifier类首先利用pickle.load()函数在初始化中导入了一个classifier_model,返回的是model和class_names,然后再进行类别的判定。所以这里的重点就是,这个classifier_model是个啥?
在该文件的第46行给出了:

这下明白了,这里面放的就是人脸特征。那么这个特征是怎么来的呢?答案在”export_embeddings.py”中。

在这个文件的说明部分,我们可以很明白的看出,该文件是要制作一个embeddings.npy,一个labels.npy和label_strings.npy文件。
具体在main函数总有这段代码:

可以看到,其将输入数据进行了提取特征的操作,然后将特征放入一个大的numpy中emb_array,并且也把label转化为numpy(123行),然后将结果写入.npy文件,也就是125-128行在做的事情。
建立人脸特征库
依据这个思路,我们大致明白了,我们要做的一个人脸特征库,就是两个文件,分别是存储特征的feature.npy和一个存储label的label.npy。
要构建人脸特征库,首先得有人脸图片。
这里我们其实有两种做法:
利用我们之前训练的样本,每个人取出其中的>10张图像,这部分图像要包含同一个人不同角度和姿态、光照下的照片,每张图片生成一个特征向量,把这些特征向量都保存成库中的特征。
同样取>10张的照片,将这些照片计算完特征向量之后,进行平均,只保存最终的一个特征向量。
这两种方法按理说都可以,方法一注重的各个特征之间的区分度,相当于建立一个完备的集合。方法二注重消除特征差异带来的不一致,采用平均向量来表示。个人感觉前者会好点,毕竟没有对后者进行试验。
总而言之,我们现在需要对每个人取假设20张图像,那么四个人一共80张。还和从前一样,放到四个文件夹中,每个文件夹为一类。
然后就可以使用类似的方法,将每一类的每个人的人脸特征提取出来,保存为一个大的矩阵,作为一个人的特征,一共做四次,就生成了一个4 × \times× 20 × \times× 512 大小的numpy。4表示4个人,20表示每个人20个特征,512表示每个特征有512个维度。
代码如下:

至此,我们就生成了人脸特征库。
人脸识别
终于到了最后一步,进行1:N的人脸识别
这部分其实就比较简单了,做法就是,首先加载我们的人脸库,然后送入图像,计算该图像的特征,然后将特征与人脸库中的特征进行欧氏距离的计算,如果这个距离在阈值范围之内,则看其与哪个人的距离最近,然后选择距离最近的那个人作为判定结果;如果距离大于阈值,则判定该人不再库中,直接拒识就好了。
代码如下:
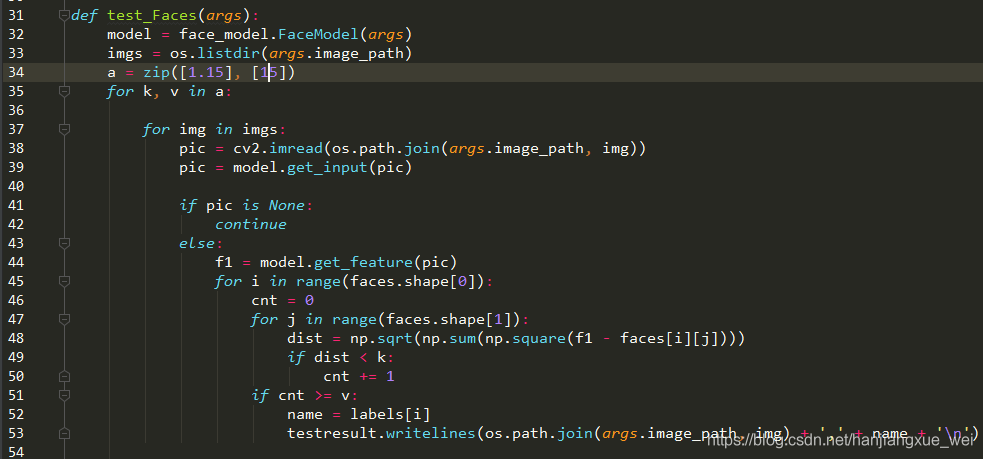
实际使用的时候还是有点差异。我这里设置了阈值为1.15和15。1.15好理解,就是我们算出来的阈值,但是这个15是什么意思呢?
假设库中的某个人有20个特征,那么如果输入图像计算出来的特征与这20个特征之中的15个距离小于阈值才能判定为该人。只有这两个条件都满足,才能判定为该库中的人。因为实际中,我们不可能有所有人的脸,那么只有使用不同的限制条件来判定,才能在一定程度上保证准确率。开个玩笑,比如将张震岳扔进去,极有可能其与詹姆斯的阈值小于1.15,但是不可能与詹姆斯的15个以上的特征都相似。所以可以通过第二个条件判定,进行拒绝。
当然,如果你说假如确实出现都相似的情况了,那岂不是识别失败了?对,就是失败了。这只是一个demo,并不是一个解决方案 。关于人脸识别还有很多知识内容,需要投入很多精力去研究,此文仅仅是一个探索案例。
花了一段时间完成这几篇博客,主要是对自己做的内容的一个总结,并且也为很多想入门的提供一个简单的demo,详细细节还需要深入研究探索。
————————————————
版权声明:本文为CSDN博主「hanjiangxue_wei」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/hanjiangxue_wei/article/details/86566497